 dev
devPico-8 needs constants
The pico-8 fantasy console runs a modified version of lua that imposes limits on how large a cartridge can be. There is a maximum size in bytes, but also a maximum count of 8192 tokens. Tokens are defined in the manual as
The number of code tokens is shown at the bottom right. One program can have a maximum of 8192 tokens. Each token is a word (e.g. variable name) or operator. Pairs of brackets, and strings each count as 1 token. commas, periods, LOCALs, semi-colons, ENDs, and comments are not counted.
The specifics of how exactly this is implemented are fairly esoteric and end up quickly limiting how much you can fit in a cart, so people have come up with techniques for minimizing the token count without changing a cart’s behaviour. (Some examples in the related reading.)
But, given these limitations on what is more or less analogous to the instruction count, it would be really handy to have constant variables, and here’s why:
1 2 3 4 5 6 7 8 9 | |
1 2 3 4 5 6 7 8 9 | |
The first excerpt is a design pattern I use all the time. You’ll probably recognize it as the simplest possible implementation of an enum, using global variables. All pico-8’s data — sprites and sounds, and even builtins like colors — are keyed to numerical IDs, not names. If you want to draw a sprite, you can put it in the 001 “slot” and then make references to sprite 001 in your code, but if you want to name the sprite you have to do it yourself, like I do here with the sfx.
Using a constant as an enumerated value is good practice; it allows us to adjust implementation details later without breaking all the code (e.g. if you move an sfx track to a new ID, you just have to change one variable to update your code) and keeps code readable. On the right-hand side you have no idea what sound 024 was supposed to map to unless you go and play the sound, or label every sfx call yourself with a comment.
But pico-8 punishes you for that. That’s technically a variable assignment with three tokens (name, assignment, value), even though it can be entirely factored out. That means you incur the 3-token overhead every time you write clearer code. There needs to be a better way to optimize variables that are known to be constant.
What constants do and why they’re efficient in C
I’m going to start by looking at how C handles constants, because C sorta has them and lua doesn’t at all. Also, because the “sorta” part in “C sorta has them” is really important, because the c language doesn’t exactly support constants, and C’s trick is how I do the same for pico-8.
In pico-8 what we’re trying to optimize here is the token count, while in C it’s the instruction count, but it’s the same principle. (Thinking out loud, a case could be made that assembly instructions are just a kind of token.) So how does C do it?
In C, constants are handled “at compile time”, meaning after you’re finished writing the program but before a computer is actually running it. C’s “compile time” is actually a process involving a number of programs consuming each others’ outputs:
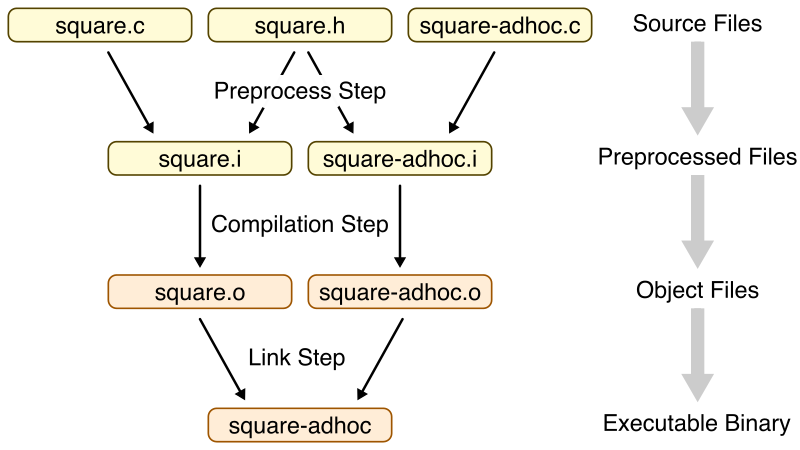 from Cornell University
from Cornell University
What we care about here is that first step, where square.c is processed into square.i by the preprocessor. The preprocessor is a program that processes C source code into an intermediate format, which importantly is still human-readable C code, before sending that through the rest of compilation. Here’s an extremely simple example with constants:
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 | |
The C preprocessor is extremely powerful and handles a lot of this “templatizing” for C code, but as you can see above, what it’s essentially doing is just a find/replace. If we can do that same thing in Pico-8, I’m happy.
Writing a new preprocessor
I looked into writing a feature for picotool for a while that would add support for a feature like this, but ultimately decided against it. Picotool was attractive because it already understood p8 syntax and could build syntax trees, but preprocessing like this didn’t end up fitting well. And then I quickly decided against writing a preprocessor from scratch at all.
Rigging up a preprocessor I already had lying around someplace
Jinja is a generic text file templating language that can easily do what we want here and quite a bit more. It’s usually used for HTML (or sometimes yaml, in ansible) but it’s completely generic and will happily process pico-8 carts out of the box.
We can use Jinja to render out p8 files from p8.j2 templates. This turns the runnable .p8 text file into an intermediate artifact rather than the original source code. So, instead of writing and running file.p8 (and possibly later minifying that to file.min.p8), you write file.p8.j2, run Jinja to create the derivative file file.p8, and run that in the console. It adds a processing layer.
Here it is
j2 is actually a script I have on my path for generically rendering all kinds of templates, but I tweaked it slightly to add a “pico-8 mode” flag that makes minor syntax changes.
As demonstration, here are some example cases from my recent game Heart&:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
I’ll go over these cases one by one in a moment, but for now, notice that the rendered output is shorter than the source file on the left. This is unusual for templating languages; usually the goal is to generate a complex output document with a concise template, but here we’re trying to compress information.
This does way more than constants!
There are a few obvious examples of constant-like removing-the-name right away. sfx_dmg is a simple constant; this is the id of the sfx used for the damage noise.
invuln_frames looks like another example of this, but it’s also a gameplay setting. This way, all the variables for properties you want to tweak during testing can be moved to the top of your file (or wherever you want them) without wasting a name on a variable in the final version. Templating can be used to remove these single-assignment variables without loss of clarity, which is important. This technique works on any single-token or single-use variable that never gets reassigned.
fpb stands for frames per beat, which is a nightmare even just to estimate. The song itself (which I’m counting at 8 notes per beat) plays at a speed of “13”. “Speed”, as handled by Pico-8, seems to be a multiplier on the length of each note in samples. In practice, it comes to 1/120.4 seconds.
so fpb = (fps/(speed/(120.4/bpm)))
or fpb = ( 60/( 13/(120.4/ 8)))
I don’t want to be computing that at runtime, but I also don’t want to lose my logic if I tweak something later. So I keep the expression but put it in a template. Note also that arithmetic is done inline at lifespan = "{{ fpb * 4 }}" before rendering!
--% with r = 50 creates a local variable scoped within the with block. This is essentially the same function as previous — treating a value as a setting variable without wasting a name — but scoped within a block, so I don’t worry about any weird side effects of having a set r variable later.
Finally, render_debug lets me optionally disable large hunks of debug-only code before I compile the final version. There are debug graphics and things that don’t need to be in the final game at all — they would just be wasting space — and so the toggle flag lets me remove the tokens themselves without having to manually delete and re-insert code at dozens of different points every time I test.
Expression evaluation
Here’s something tricky: Jinja2 evaluates expressions, which C’s preprocessor doesn’t, even though the outcome is usually the same:
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 | |
1 2 3 4 | |
This is exactly what we want! If we did arithmetic in a constant declaration, but it substituted in all the tokens in the expression instead of the expression’s value, that wouldn’t save all the tokens available. Phew!
Moving weirdness to templates is better practice than unreadable code
The optimization document I mentioned earlier, PICO-8-Token-Optimizations, reads
seleb / PICO-8-Token-Optimizations | github.com A few of these are pretty obvious, a few of them are not that obvious. Almost all of them make your code more unreadable, harder to edit, and would generally be considered “bad practice” in a less constrained system.
Making your code unreadable with optimizations is bad practice. We can’t change the constraints of Pico-8 (yet!) but we can take the manual labor out of the process.
Implementation!
So, when I sit down to write code, my current setup is something like this:
- One terminal window running the background, running the alias
react j2demo.p8.j2 "j2 j2demo.p8.j2 --pico8", which waits for the file to change and re-runsj2as soon as it does. (Implementation of that alias is weird, and out of scope of this article.)- Alternatively, if you have an editor with configurable save hooks, you can rig up j2 to run automatically when you save .p8.j2 files.
- Sublime Text configured as a Pico-8 IDE
- Configured with a
debugbuild command that opens the current .p8 file in a new pico-8 window (with acmdinstance, to work around Pico-8 not playing with streams properly) - Editing my
.p8.j2file in the editor in one pane, lettingreactregenerate the.p8file in the other pane within a second or two of saving - Ctrl+r in pico-8 running the
.p8cart to refresh after saving
- Configured with a
You can pick up j2 for yourself if you want.