 cyber
cyber- AI
- environmentalism
- big
- tech
- technical Series: Is AI eating all the energy? ad: “AI: "it’s capitalism, stupid"“
Part 2: Growth, Waste, and Externalities
The AI tools are efficient according to the numbers, but unfortunately that doesn’t mean there isn’t a power problem. If we look at the overall effects in terms of power usage (as most people do), there are some major problems. But if we’ve ruled out operational inefficiency as the reason, what’s left?
The energy problems aren’t coming from inefficient technology, they’re coming from inefficient economics. For the most part, the energy issues are caused by the AI “arms race” and how irresponsibly corporations are pushing their AI products on the market. Even with operational efficiency ruled out as a cause, AI is causing two killer energy problems: waste and externalities.
Increasing costs
First, where are energy costs ballooning?
Performance demand
Previously, I said that overall energy use varies because of the volatile factors that affect it:
While it’s true that there’s no monotonic trend in any one direction, experts do project (based on assumption of increasing demand) that the overall energy use will increase in the coming years. As the demand for AI products grows, so do the power requirements. This is contributing to an increase in overall demand for electricity production.
Training growth
While there’s still a huge spread between individual models, the overall trend is that models have become increasingly complex, and so increasingly expensive to train.
This is mostly seen in global-scale “frontier” and “omni” models, like ChatGPT and Llama. There is no limit to how energy-expensive training can be made. (That’s the “frontier” frontier models are pushing: how big the models can get.) Until you run out of data you can always train on more and more data points. And the more data points you use, the more expensive training gets.
I touched on this briefly in Part 1:
Training costs are proportional to the amount of data the model is trained on. The more data points there are, the longer the training takes. This means that it’s always possible to make training more expensive by throwing more data in. …
…
In 2022, training costs for the BLOOMz model family of small LLMs were benchmarked, and the range for total training costs was 11,000 kWh to 51,586 kWh…But it is possible to pour massive amounts of energy into training language models. The more data you use as input, the more work is required to train a satisfactory model. In more recent history, Meta’s Llama 3 large language model’s small and large sizes were trained in 2024 for 1.3 and 6.4 million 700-watt GPU hours, respectively, with a maximum theoretical power usage of 910,000 kWh and 4,480,000 kWh.
Unfortunately, marginal gains in model quality require staggering amounts of electricity.
I don’t have any data for “model quality”, so please excuse my very unscientific sketch here, but it seems to me that the pattern is something like this:

Smaller and smaller diminishing returns in quality require a non-diminishing energy cost. This makes bigger and bigger large language models (LLMs) less proportionally valuable.
And as LLMs keep getting bigger, the costs grow higher and higher.
As it says on the tin, “Training Compute of Frontier AI Models Grows by 4-5x per Year” estimates that the total complexity of training AI models (not compensating for efficiency improvements) has been 4-5x per year:
Jaime Sevilla and Edu Roldán, “Training Compute of Frontier AI Models Grows by 4-5x per Year”
…
We tentatively conclude that compute growth in recent years is currently best described as increasing by a factor of 4-5x/year. We find consistent growth between recent notable models, the running top 10 of models by compute, recent large language models, and top models released by OpenAI, Google DeepMind and Meta AI.There are some unresolved uncertainties. We cannot rule out that the overall trend of compute might have accelerated. We also find evidence of a slowdown of growth in the frontier around 2018, which complicates the interpretation, and recent frontier growth since 2018 is better described as a 4x/year trend. We also find a significantly faster trend for notable language models overall, which have grown as fast as 9x/year between June 2017 and May 2024. However, when focusing on the frontier of language models, we see that the trend slows down to a ~5x/year pace after the largest language models catch up with the overall frontier in AI around mid-2020.
All in all, we recommend summarizing the recent trend of compute growth for notable and frontier models with the 4-5x/year figure. This should also be used as a baseline for expectations of growth in the future, before taking into account additional considerations such as possible bottlenecks or speed-ups.
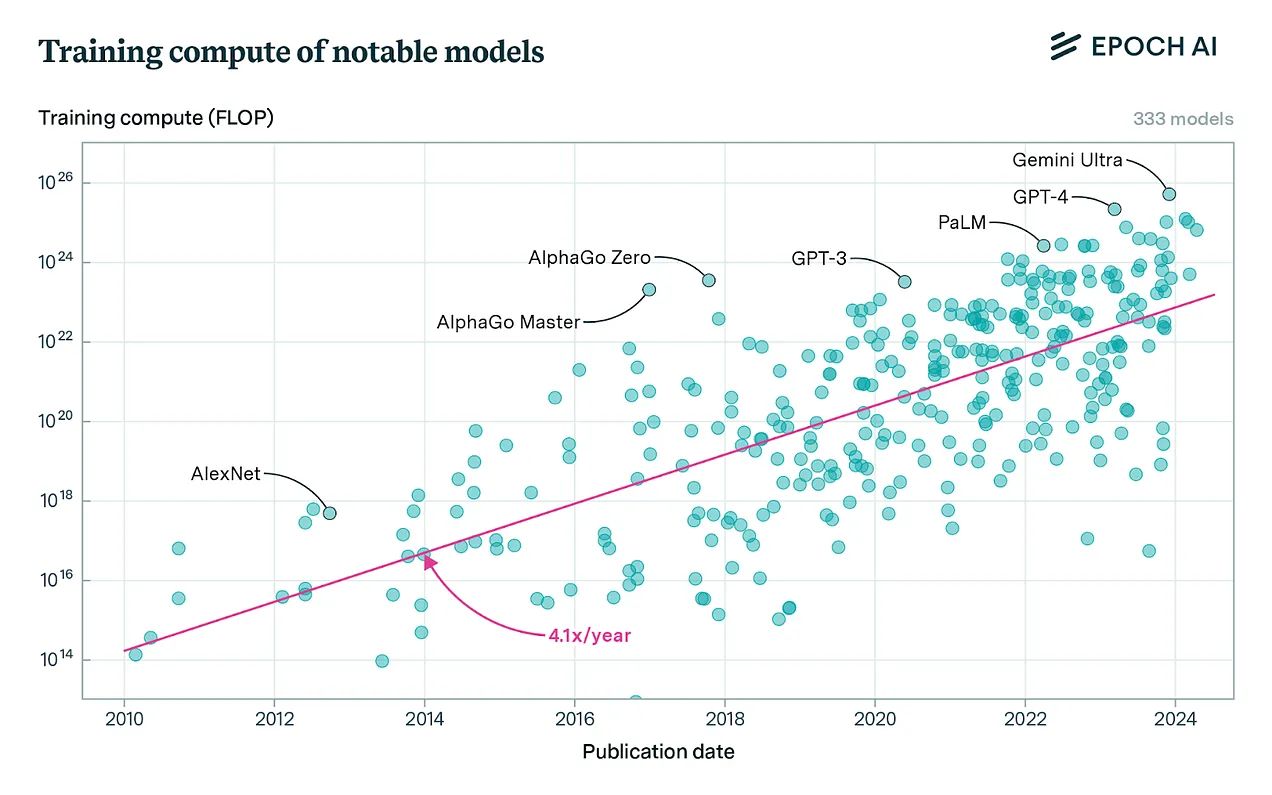
For another view of the same EpochAI data, see Computation used to train notable AI systems, by affiliation of researchers, an interactive graph from Our World in Data.
Note this is measuring in floating point operations (FLOP), which is a kind of “operation”, not energy. The total energy use would also have to factor in the change in energy/operations over time, which flattens the line. In our formula, the increase in complexity measured here corresponds to an increase in operations/job:
So that increasing model complexity is a factor that we should expect will push up the net energy required to train (but not use) models.
Reduced cost per operation lowers net consumption
But to jerk you around one more time, there are yet more factors pushing costs down, so it’s not quite as bad as it looks.
Demand and efficiency (meaning lower cost per operation) push the overall power usage in opposite directions. Theoretically, if efficiency improved fast enough, it could actually outpace demand and cause overall power usage to stay steady, or even go down, even as performance demands increase.
In fact, prior to the recent data center boom, that’s exactly what’s been happening:
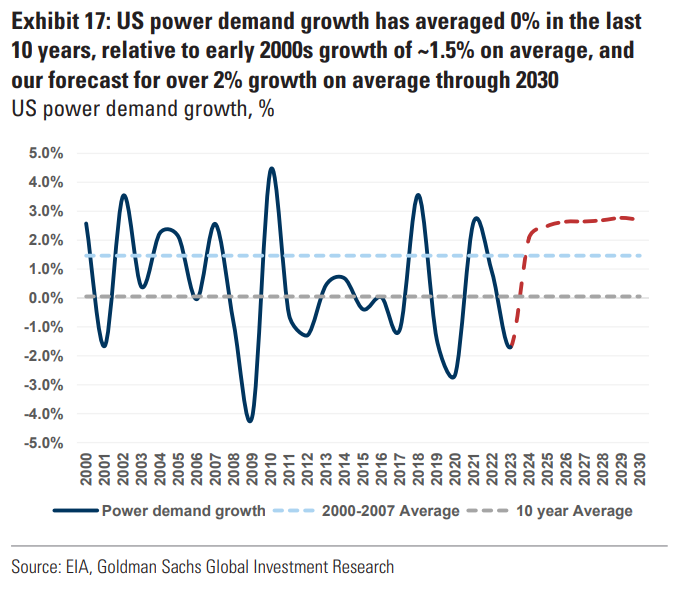
Despite the increase in demand for electrical performance, the change in power demand has averaged 0% for the last ten years due to efficiency improvements outpacing increasing usage. How cool is that?
As seen in this graph from United States Data Center Energy Usage Report (2016), if energy efficiency had remained at 2010 levels, annual electricity use would have skyrocketed:
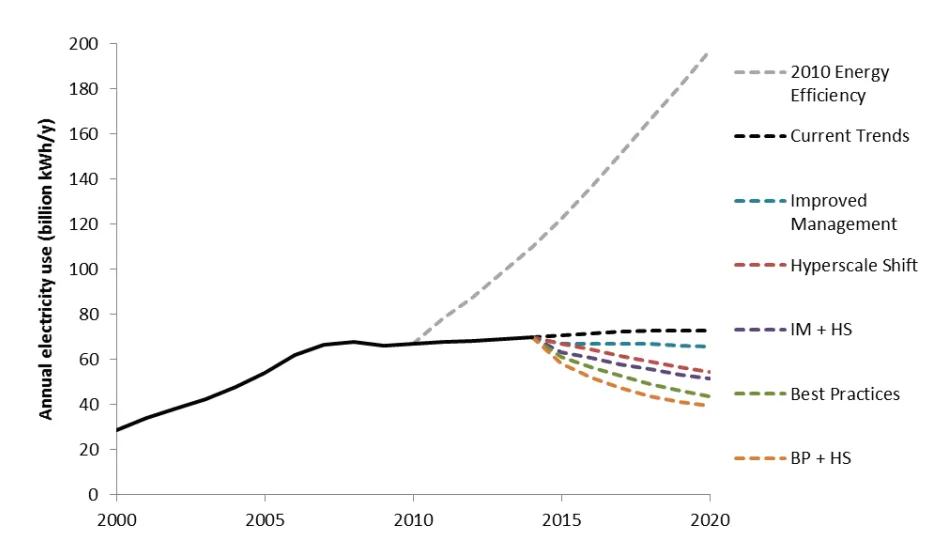
But, in reality, power consumption stayed almost level because efficiency increased alongside demand. And, as the report describes, usage could be lowered even further by implementing more efficiency measures, without ever affecting performance demand (e.g. by artificially restricting use).
Systemic limits
Training costs are growing fast. On the other hand, this growth is necessarily limited. Even if we had infinite power infrastructure and corporations could increase their power usage as much as they wanted, they’d still have to make it profitable, or they simply couldn’t afford to buy the power.
As laid out by de Vries:
de Vries, A. (2023). The growing energy footprint of artificial intelligence. Joule, 7(10), 2191–2194. https://doi.org/10.1016/j.joule.2023.09.004 … However, this scenario assumes full-scale AI adoption utilizing current hardware and software, which is unlikely to happen rapidly. Even though Google Search has a global reach with billions of users, such a steep adoption curve is unlikely. Moreover, NVIDIA does not have the production capacity to promptly deliver 512,821 A100 HGX servers, and, even if it did, the total investment for these servers alone for Google would total to approximately USD 100 billion. Over 3 years, the annual depreciation costs on a USD 100 billion AI server investment would add up to USD 33.33 billion. Such hardware expenses alone would significantly impact Google’s operating margin. … For Google Search, this would translate to an operating margin of USD 42.25 billion. The hardware costs, coupled with additional billions in electricity and other costs, could rapidly reduce this operating margin to zero. In summary, while the rapid adoption of AI technology could potentially drastically increase the energy consumption of companies such as Google, there are various resource factors that are likely to prevent such worstcase scenarios from materializing.
The cost of energy consumption can’t consistently outpace profit, or the company would lose money. The amount that can feasibly be spent is always locked to how profitable that use actually is (at least, in the long run).
For a demonstration of this point, let’s look at Bitcoin and its energy use. If you compare the energy consumption of bitcoin and the price history of bitcoin, you’ll find they’re roughly the same shape:
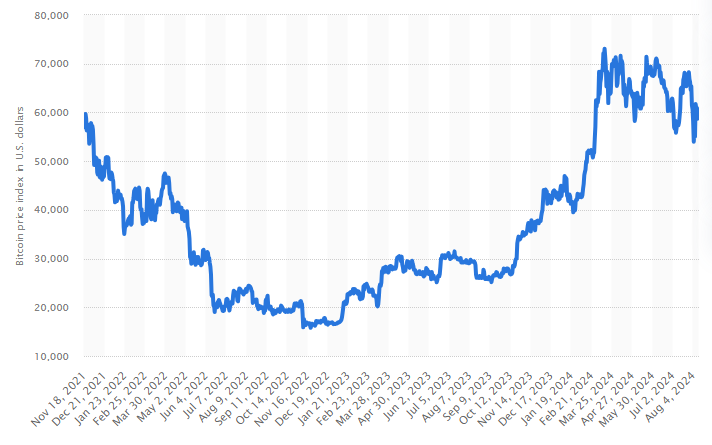
It should be intuitive that the energy consumption of bitcoin tracks its value. Bitcoin miners aren’t willing to spend more on energy than the bitcoin they’d mine is worth. The net revenue creates a hard ceiling, because no one wants negative profit.
I chose bitcoin for this example because its worth is a simple number and so is easily quantifiable. (The “value of AI” is not so easily plotted.) But in the same way as bitcoin, we should expect the energy use of AI to be capped by its value. If companies don’t expect billions of revenue from training an AI, they’re not going to spend billions on power.
Quoting Kyle again,
Kyle Orland, Taking a closer look at AI’s supposed energy apocalypse | Ars Technica …there are economic limits involved in the total energy use for this kind of technology. … A similar trend [to bitcoin] will likely guide the use of generative AI as a whole, with the energy invested in AI servers tracking the economic utility society as a whole sees from the technology.
…
In the end, though, these companies are in the business of making a profit. If customers don’t respond to the hype by actually spending significant money on generative AI at some point, the tech-marketing machine will largely move on, as it did very recently with the metaverse and NFTs. And consumer AI spending will have to be quite significant indeed to justify current investment—OpenAI projected losses of $1 billion in 2023, even as annualized revenues hit $1.6 billion by the end of the year.
This is why people like Ed Zitron are convinced OpenAI is a bubble. If OpenAI has invested more money in AI than it’s worth, and they can’t make that money back — whether through generating real value or market capture — they’re going to fail, and other companies will learn not to make the same mistake.
Growth, regardless
So can we stop there? The invisible hand of the market will ensure businesses always use resources optimally, problem solved.
No. Because corporations aren’t rational actors, and we are in the middle of a Moment.
AI is a new market to capture, but it also represents an unprecedented amount of influence corporations can wield against the people who use its products. And smaller tech companies (with a lot of cumulative venture capital) are racing to integrate other AI services into their various apps. So tech companies are desperate to capture the market.
This is the land rush: tech companies scrambling for control of commercial AI. There is suddenly a valuable space to be captured, and every company is desperate to control as much of it as possible. This is a moment that rewards aggressive action and punishes cautiousness. This is what the “move fast and break things” model is built for. So rationality be damned, tech companies are all spending as much as they can on building the biggest, most expensive AI models imaginable right now. The promises of huge returns from speculative investment breaks the safety net of rationalism.
And so now, everything clicks into place. Every tech company is desperate to train the biggest and most expensive proprietary models possible, and they’re all doing it at once. Executives are throwing more and more data at training in a desperate attempt to edge over competition even as exponentially increasing costs yield diminishing returns.
Model training consumes vast amounts of energy for the sole purpose of gaining a competitive edge. The value isn’t that a better tool is created, the value is that you use tool A instead of tool B. In these cases the goal isn’t to produce something significantly more useful, it’s to shift who has what market share. Corporations are willing to place very high value — and spend vast quanties of resources on — goals that provide very low overall utility.
And since these are designed to be proprietary, even when real value is created the research isn’t shared and the knowledge is siloed. Products that should only have to be created once are being trained many times over because every company wants to own their own.
Profit is always the top priority, and companies are speculating that AI is a bottomless pit of profit. This means there is a spike of irresponsibly high demand for energy, and things have gotten weird. Bad-weird.
Ramifications and externalities
So far I’ve been talking about the easy-to-quantify energy use in kWh, but there are “costs” that companies offload onto the community at large. These are called externalities, which is the same category that includes things like pollution. An externality is when one activity directly causes a cost that is offloaded onto a party uninvolved in the original activity, often the general public. Privatized gain, socialized loss.
For example, the cost of new data centers to supply computing power is not just the electricity they consume and pay for. There are other negative consequences that affect everyone, like increased electricity prices and a higher risk of grid failure and outages.
Increased electricity demand
Reportedly, the AI boom is causing an “unprecedented demand” for power. Goldman Sachs announces “US power demand growth expanding to levels not seen in decades”, and it’s “outstripping the available power supply”.
This is true, but for a surprising reason: it’s unusual for power demand to increase at all, as I’ve previously mentioned. For the past 10 years, US power demand growth has changed by an average of 0%. Now, though, we’re seeing data center expansion cause an increase in demand of around 2.5%:
For estimating overall growth in power consumption, including compensating for increased demand, there are much more complex prediction models whipped up by guys whose whole thing is just making money off prediction models. Assuming there’s no crash and the AI industry continues to grow, uses falling under the broad category of “AI” are expected to reach a high ~20% of that new demand (~0.5% overall):
Goldman Sachs, “Generational growth: AI, data centers and the coming US power demand surge”, Apr 2024 US power demand likely to experience growth not seen in a generation.
Not since the start of the century has US electricity demand grown 2.4% over an eight-year period, with US annual power generation over the last 20 years averaging less than 0.5% growth. We believe this is on track to change through the end of the decade, led by a surge in data center demand for power and complemented by electrification, industrial re-shoring/manufacturing activity. Growth from AI, broader data demand and a deceleration of power efficiency gains is leading to a power surge from data centers, with data center electricity use expected to more than double by 2030, pushing data centers to 8% of US power demand vs. 3% in 2022.
Exhibit 1: After being flattish for 2015-19, we see power demand from data centers more than tripling in 2030 vs. 2020, with an upside case more than double the base case depending in part on product efficiencies and AI demand Data center electricity consumption, TWh (LHS) and 3-year rolling average power efficiency gains yoy, % (RHS)
…
We assume power demand from AI rises about 200 TWh in 2024-30 (bear/bull case of 110-330 TWh), with AI representing about 20% of overall data center power demand by 2030 in our base case. We see a wide range in our bear/bull scenario driven by uncertainty over demand and power efficiency. As demand for AI training grows in the medium term and for inference longer term, we see demand growth well exceeding the efficiency improvements that are leading to meaningful reductions in high power AI server power intensity.
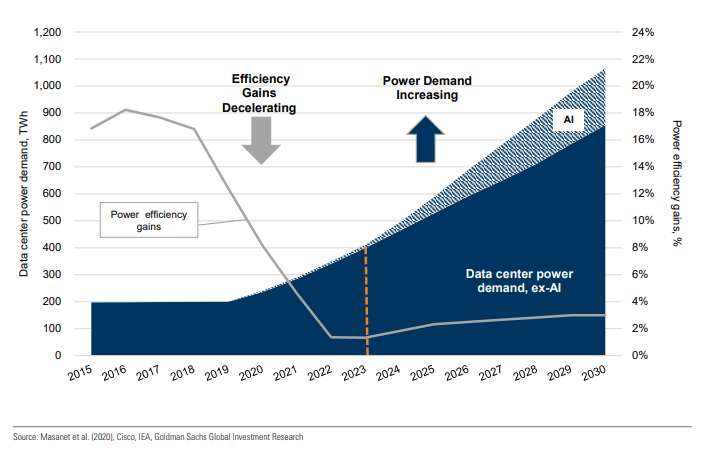
(The currently small AI energy footprint is also where numbers like “AI is expected to suck up 500% more energy over the next decade” come from; the slice that the predicted energy use is five times larger than is pretty small at the beginning.)
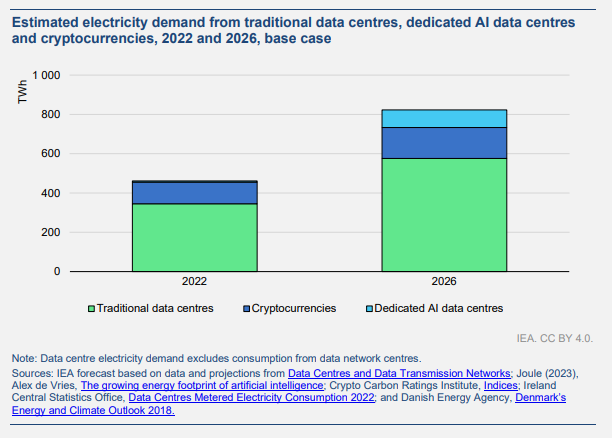
And that power has to come from somewhere.
New power infrastructure
The existing power grid cannot keep up with the projected electricity demand of AI at scale. And power infrastructure is already seeing that demand:
AI Is Already Wreaking Havoc On Global Power Systems | Bloomberg In late 2022, [Dominion Energy Inc., the power company that services Loudoun County] filed a previously unreported letter to its regulators asking for permission to build new substations and power lines to serve “unprecedented” load growth. In the letter, Dominion said it experienced 18 load relief warnings in the spring of that year. These warnings occur when the grid operator tells the company that it might need to shed load, the technical term for the controlled interruption of power to customers, which could include rotating outages.
“This is far outside of the normal, safe operating protocol,” Dominion told regulators.
The supply of energy is limited, and new data centers simply can’t be built fast enough, because the power supply isn’t there yet. New projects, including data centers, can expect to wait in queues for 4 years for the power supply they want:
Goldman Sachs, “Generational growth: AI, data centers and the coming US power demand surge”, Apr 2024 …lengthy interconnection queues remain a challenge to connecting new projects to the grid, and expediting the permitting/approval process for transmission projects will be key to alleviate it. Elsewhere, we see similar potential growth constraints from natural gas transmission infrastructure construction, specifically long-dated timelines, permitting challenges, and environmental / landowner litigation. In our view, the most top of mind constraint for natural gas is construction and permitting timelines where we see an average lag of ~4 years from the project announcement date to in-service date which means the earliest capacity additions, if announced today, would not be in-service until ~2028.
AI Is Already Wreaking Havoc On Global Power Systems | Bloomberg The almost overnight surge in electricity demand from data centers is now outstripping the available power supply in many parts of the world, according to interviews with data center operators, energy providers and tech executives. That dynamic is leading to years-long waits for businesses to access the grid as well as growing concerns of outages and price increases for those living in the densest data center markets.
…
The surge in demand is causing a backlog. Data center developers now have to wait longer to hook their projects up to the electric grid. “It could be as quick as two years, it could be four years depending on what needs to be built,” Dominion Energy Virginia president Edward Baine said in an interview.
But, because it’s land rush time, corporations are desperate not to wait. It doesn’t matter how much it costs, they demand to move at full speed right now. This means a lot of things are happening at once:
New clean energy
Since existing energy sources (namely natural gas) can’t keep up, a lot of companies are investing in research on new and alternative energy sources. Because the demand is so intense, companies are willing to spend huge amounts of money on research, including into historically neglected sources like nuclear fusion:
AI is exhausting the power grid. Tech firms are seeking a miracle solution. [Microsoft] and its partners say they expect to harness fusion by 2028, an audacious claim that bolsters their promises to transition to green energy …
In the face of this dilemma, Big Tech is going all-in on experimental clean energy projects that have long odds of success anytime soon. In addition to fusion, tech giants are hoping to generate power through such futuristic schemes as small nuclear reactors hooked to individual computing centers and machinery that taps geothermal energy by boring 10,000 feet into the Earth’s crust.
…
At the World Economic Forum conference in Davos, Switzerland, in January, Altman said at a Bloomberg event that, when it comes to finding enough energy to fuel expected AI growth, “there is no way to get there without a breakthrough.”Altman, meanwhile, is spending hundreds of millions of dollars to develop small nuclear plants that could be built right on or near data center campuses. Altman’s AltC Acquisition Corp. bankrolled a company Altman now chairs called Oklo, which says it wants to build the first such plant by 2027.
Gates is the founder of his own nuclear company, called TerraPower. It has targeted a former coal mine in Wyoming to be the demonstration site of an advanced reactor that proponents claim would deliver energy more efficiently and with less waste than traditional reactors. The project has been saddled with setbacks, most recently because the type of enriched uranium needed to fuel its reactor is not available in the United States.
…
For now, Helion is building and testing prototypes at its headquarters in Everett, Wash. Scientists have been chasing the fusion dream for decades but have yet to overcome the extraordinary technical challenges. It requires capturing the energy created by fusing atoms in a magnetic chamber — or in Helion’s case, a magnetized vacuum chamber — and then channeling that energy into a usable form. And to make it commercially viable, more energy must be produced than is put in.
The appetite for so much new energy is so high that companies are really hoping to land on an energy breakthrough. This is actually kind of cool. Nuclear energy is historically underutilized in America, and a renewed push toward nuclear power could signal a major shift away from dirtier fuels like coal and gas.
Old dirty energy
The bad news is the nuclear breakthrough hasn’t happened yet, and tech companies are still demanding enormous amounts of power as soon as they can get it. The land rush means companies are unwilling to temporarily slow growth and use the legitimate supply of energy as it becomes available.
This means sucking as much power as possible out of the existing infrastructure.
Horrifyingly, this includes coal plants that were scheduled for decommission but are now continuing to run in order to meet this immediate demand.
AI is exhausting the power grid. Tech firms are seeking a miracle solution. In the Salt Lake City region, utility executives and lawmakers scaled back plans for big investments in clean energy and doubled down on coal. The retirement of a large coal plant has been pushed back a decade, to 2042, and the closure of another has been delayed to 2036.
…
The region was supposed to be a “breakthrough” technology launchpad, with utility PacifiCorp declaring it would aim to replace coal infrastructure with next-generation small nuclear plants built by a company that Gates chairs. But that plan was put on the shelf when PacifiCorp announced in April that it will prolong coal burning, citing regulatory developments that make it viable.“This is very quickly becoming an issue of, don’t get left behind locking down the power you need, and you can figure out the climate issues later,” said Aaron Zubaty, CEO of California-based Eolian, a major developer of clean energy projects. “Ability to find power right now will determine the winners and losers in the AI arms race. It has left us with a map bleeding with places where the retirement of fossil plants are being delayed.
A spike in tech-related energy needs in Georgia moved regulators in April to green-light an expansion of fossil fuel use, including purchasing power from Mississippi that will delay closure of a half-century-old coal plant there. In the suburbs of Milwaukee, Microsoft’s announcement in March that it is building a $3.3 billion data center campus followed the local utility pushing back by one year the retirement of coal units, and unveiling plans for a vast expansion of gas power that regional energy executives say is necessary to stabilize the grid amid soaring data center demand and other growth.
In Omaha, where Google and Meta recently set up sprawling data center operations, a coal plant that was supposed to go offline in 2022 will now be operational through at least 2026. The local utility has scrapped plans to install large batteries to store solar power.
“When massive data centers show up and start claiming the output of a nuclear plant, you basically have to replace that electricity with something else.”
I’m going to repeat that quote, because it hits the issue exactly on the head, even if the speaker hasn’t realized the ramifications:
“This is very quickly becoming an issue of, don’t get left behind locking down the power you need, and you can figure out the climate issues later,” said Aaron Zubaty, CEO of California-based Eolian, a major developer of clean energy projects. “Ability to find power right now will determine the winners and losers in the AI arms race.
And instead of being slapped down for going back on their word in the worst way possible, the energy industry is just making more money off it:
Internet data centers are fueling drive to old power source: Coal …antiquated coal-powered electricity plants that had been scheduled to go offline will need to keep running to fuel the increasing need for more power, undermining clean energy goals.
…
After [PJM Interconnection, the regional grid operator] tapped [Dominion Energy] to build a 36-mile-long portion of the planned power lines for $392 million, FirstEnergy announced in February that the company is abandoning a 2030 goal to significantly cut greenhouse gas emissions because the two plants are crucial to maintaining grid reliability.The news has sent FirstEnergy’s stock price up by 4 percent, to about $37 a share this week, and was greeted with jubilation by West Virginia’s coal industry.
…
Critics say it will force residents near the coal plants to continue living with toxic pollution, ironically to help a state — Virginia — that has fully embraced clean energy. And utility ratepayers in the affected areas will be forced to pay for the plan in the form of higher bills, those critics say.But PJM Interconnection, the regional grid operator, says the plan is necessary to maintain grid reliability amid a wave of fossil fuel plant closures in recent years, prompted by the nation’s transition to cleaner power.
And companies aren’t just burning coal to fuel power-hungry data centers, they’re actively building new data farms in areas that already primarily use coal power:
AI Is Already Wreaking Havoc On Global Power Systems | Bloomberg When Rangu Salgame looks at Malaysia, he sees the next Virginia “in the making.” Johor, the southernmost state in peninsular Malaysia, has a policy to speed up clearances for data centers. Crucially, it’s also a short drive to Singapore, a longtime data center hub that imposed a moratorium for several years on new facilities to manage energy growth on the tiny island.
Once a sleepy fishing village, the suburbs of the city of Johor Bahru are now marked by vast construction sites. Microsoft and Amazon are investing in the region, as is Salgame’s company, Princeton Digital Group (PDG). At Sedenak Tech Park, a sprawling complex about 40 miles south of Johor Bahru’s city center, towering cranes dot the sky. PDG’s new 150 megawatt data center occupies one corner of the park, across from similar facilities from other providers.
But even markets eager to streamline data center buildout face constraints. What’s missing in Johor, especially for an industry like tech that is known for its climate pledges, is renewable energy. The power supply at Sedenak comes from Tenaga Nasional Berhad, which uses coal or gas-fired plants. While Malaysia has ambitious goals to bolster renewables, including plans to build a 500-megawatt solar farm in Johor, today it relies on coal for more than a third of its generation.
No longer green
In turn, this has collapsed companies’ green energy promises across the board. “Don’t get left behind locking down the power you need, and you can figure out the climate issues later.” Investing in AI is just too tempting.
Microsoft has abandoned its plan to become carbon neutral:
Microsoft’s AI Push Imperils Climate Goal as Carbon Emissions Jump 30% When Microsoft Corp. pledged four years ago to remove more carbon than it emits by the end of the decade, it was one of the most ambitious and comprehensive plans to tackle climate change. Now the software giant’s relentless push to be the global leader in artificial intelligence is putting that goal in peril. …
Microsoft’s predicament is one of the first concrete examples of how the pursuit of AI is colliding with efforts to cut emissions. Choosing to capitalize on its early lead in the new market for generative AI has made Microsoft the most valuable company in the world, but its leaders also acknowledge keeping up with demand will mean investing more heavily in polluting assets.
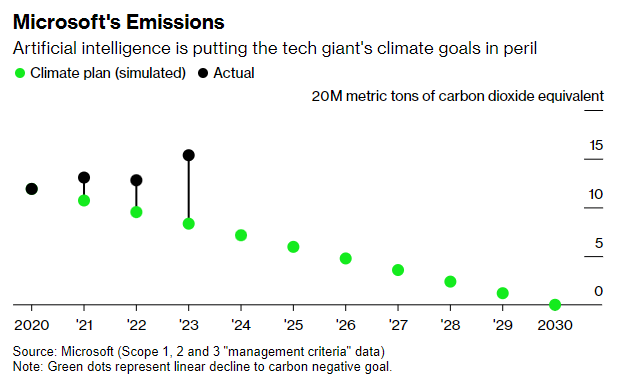
Google used to be carbon neutral, but now isn’t:
Google Is No Longer Claiming to Be Carbon Neutral The Alphabet Inc. unit has claimed that it’s been carbon neutral in its operations since 2007. The status was based on purchasing carbon offsets to match the volume of emissions that were generated from its buildings, data centers and business travel. But in its latest report, the company states: “Starting in 2023, we’re no longer maintaining operational carbon neutrality.” …
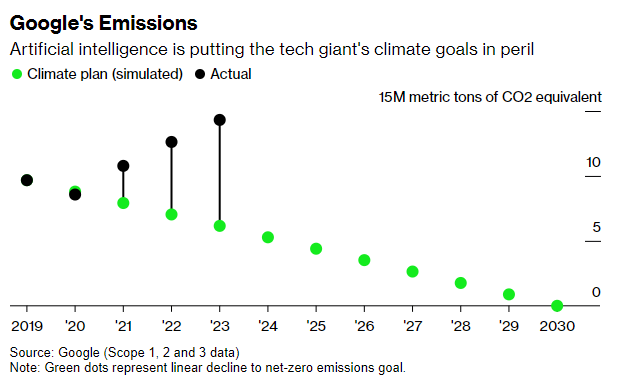
And Meta… well, Meta’s carbon emissions are rising, but they’re hiding it.
Justine Calma, “Are Meta’s carbon emissions shrinking? Depends on how you look at it” The company’s carbon footprint on paper differs from what’s happening on the ground.
Untangling companies’ environmental claims these days can be a head-spinning endeavor, and reading Meta’s latest sustainability report is no exception. Depending on how you look at it, the company’s greenhouse gas emissions either grew or fell last year.
[The numbers indicating growing emissions] reflect local pollution stemming from the electricity the company uses wherever it sets up shop. Data centers typically connect into the local power grid, so they run on the same mix of fossil fuels as everyone else. A majority of Meta’s data centers are located in the US, where 60 percent of electricity still comes from fossil fuels.
But Meta says it matches 100 percent of its electricity use with renewable energy purchases, which is how it’s able to show a much smaller carbon footprint on paper.
This is, of course, the nature of corporations. Since profit is the only goal, when responsible energy use doesn’t increase profit, they’ll choose profit every time.
Increased electricity prices
Regardless of the sources, power demand from a single industry is requiring power companies to build new infrastructure. And when power companies invest in new infrastructure, they spread that cost across all consumers in the form of rate increases. This is another externality. This time, it’s not a vague climate problem being offloaded; it’s a very tangible bill.
AI Is Already Wreaking Havoc On Global Power Systems | Bloomberg The surge in data center demand, combined with heavy investments from power companies like [Dominion Energy Inc., the power company that services Loudoun County] on new substations, transmission lines and other infrastructure to support it, are also increasing the likelihood customers will see their energy prices go up, experts say. The cost of some upgrades are typically allocated among electricity customers in an entire region, showing up as a line item on everyone’s monthly utility bill.
Goldman Sachs estimates that US utility companies will have to invest roughly $50 billion in new power generation capacity to support data centers. “That’s going to raise energy prices for both wholesale energy and retail rates,” said power market analyst Patrick Finn of energy consultancy Wood Mackenzie.
When companies make demands, you’re automatically conscripted into subsidizing them. Instead of shutting down coal plants, you get the bill for the work of building the infrastructure for more dirty energy.
Water
Another problem is water use. Producing energy in the first place requires water, but data centers themselves require significant amounts of water to run.
I think it’s important to be careful and use precise language around this, especially near phrases like “use” and “consume water”. Of course, water itself isn’t a nonrenewable resource. The concern here isn’t that we’re somehow drying out the planet. When people don’t think through this, they end up saying things like water itself is a natural resource AI depletes, which is just foolish. There is no “peak water.” There is a whole cycle about this.
The resource that data centers deplete then is available water in a region, usually called the water supply. This specifically refers to water available on-demand as part of a municipal water supply. There is often unexploited water — like atmospheric moisture, rain, and groundwater — that takes additional work to make available for distribution, but this isn’t considered part of the water supply.
Water’s primary use data centers is cooling. Because heat is a byproduct of computing, almost all of a data center’s electricity is ultimately converted to waste heat. Water cooling is significantly more energy efficient than other cooling methods like air cooling1, so it’s overwhelmingly the choice for dedicated data centers.
A Practical Approach to Water Conservation for Commercial and Industrial Facilities

At a high level, tubing is run through areas that generate heat. Cool water treated with chemicals is pumped through these tubes and absorbs the heat energy. The heated water is then sent to evaporation towers, where evaporation removes the heat as part of the state change from liquid to vapor. The remaining cooled water is (usually) chilled, cycled back into the main network, and supplemented with new makeup water to replace the volume that evaporated. Some unevaporated “blowdown” water is also intentionally removed from the circuit as part of a filtration process to prevent mineral buildup.
This process doesn’t “destroy” any water, but it does require a continual supply of input makeup water that it does not replenish. Because of the chemical treatment, the blowdown water output is non-potable and unsuitable for human consumption or even agricultural use. So overall, data centers represent a significant consumption of the water supply.
Fortunately, the makeup water it requires doesn’t have to be potable either. Some areas, like Virginia, have access to non-potable “gray water” which can be used for cooling. This replaces at least some of the demand for vital potable water.
Google, Our commitment to climate-conscious data center cooling (2022) Last year, our global data center fleet consumed approximately 4.3 billion gallons of water. This is comparable to the water needed to irrigate and maintain 29 golf courses in the southwest U.S. each year.
Wherever we use water, we are committed to doing so responsibly. This includes using alternatives to freshwater whenever possible, like wastewater, industrial water, or even seawater. We utilize reclaimed or non-potable water at more than 25% of our data center campuses. For example, in Douglas County, Georgia, we implemented a solution to cool our data center by recycling local municipal wastewater that would otherwise be deposited in the Chattahoochee River.
(Looking at their released metrics for 2021, Douglas County was the only domestic location using water reclamation.)
Unfortunately, in practice, most water used for cooling is still potable drinking water from the municipal water supply. There are several reasons for this: unlike gray water, infrastructure to supply drinking water already exists and is usually less expensive than creating new logistics to deliver recycled water (arid environments don’t have easy access to seawater), and the consistently clean potable water is better for the tubing and circulation systems.
Data centre water consumption | npj Clean Water, 2021 Data centres consume water directly for cooling, in some cases 57% sourced from potable water, and indirectly through the water requirements of non-renewable electricity generation. Although in the USA, data centre water consumption (1.7 billion liters/day) is small compared to total water consumption (1218 billion liters/day), there are issues of transparency with less than a third of data centre operators measuring water consumption.
…
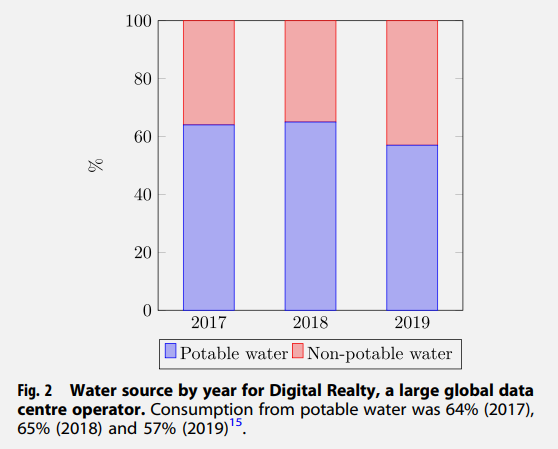
Total water consumption in the USA in 2015 was 1218 billion litres per day, of which thermoelectric power used 503 billion litres, irrigation used 446 billion litres and 147 billion litres per day went to supply 87% of the US population with potable water13.Data centres consume water across two main categories: indirectly through electricity generation (traditionally thermoelectric power) and directly through cooling. In 2014, a total of 626 billion litres of water use was attributable to US data centres4. This is a small proportion in the context of such high national figures, however, data centres compete with other users for access to local resources. A medium-sized data centre (15 megawatts (MW)) uses as much water as three average-sized hospitals, or more than two 18-hole golf courses14. Some progress has been made with using recycled and non-potable water, but from the limited figures available15 some data centre operators are drawing more than half of their water from potable sources (fig 2).
There are several different mechanisms for data centre cooling27,28, but the general approach involves chillers reducing air temperature by cooling water—typically to 7–10 °C31—which is then used as a heat transfer mechanism. Some data centres use cooling towers where external air travels across a wet media so the water evaporates. Fans expel the hot, wet air and the cooled water is recirculated32. Other data centres use adiabatic economisers where water sprayed directly into the air flow, or onto a heat exchange surface, cools the air entering the data centre33. With both techniques, the evaporation results in water loss. A small 1 MW data centre using one of these types of traditional cooling can use around 25.5 million litres of water per year32.
But data centers’ impact on local water supplies is actually particularly significant because of where the data centers tend to be built geographically. In order to reduce issues with the electric components involved, data center operators prefer environments with dry air and naturally low humidity. This means aridity is a geographical factor2 in choosing a location for a data center: arid, non-humid environments are preferable.
The problem, of course, is these arid environments are exactly the regions where the water supply is scarce. Dry, drought-prone areas like Texas and Virginia are the most stressed for water already, and taking water out of these areas’ municipal supplies is more impactful than using the same amount of water anywhere else.
 graphic from Nicolas Rapp Design Studio
graphic from Nicolas Rapp Design Studio
There’s also a Goodhart’s law side to this preference for arid climates. These areas tend to be hubs for green energy sources like wind and solar (although they lack hydroelectric power). And — in what might be a case of greenwashing — using power with that sort of green provenance makes the all-important carbon numbers go down:
Shannon Osaka, “A new front in the water wars: Your internet use” In The Dalles, Ore., a local paper fought to unearth information revealing that a Google data center uses over a quarter of the city’s water. …
According to a Virginia Tech study, data centers rank among the top 10 water-consuming commercial industries in the United States, using approximately 513 million cubic meters of water in 2018. … about a quarter [of the 513 number] is due to using water for direct cooling.
The researchers also found that a lot of data centers operate where water is scarce.
Part of the problem is that tech companies put many of these centers in areas where power is cheap and low-carbon — such as Arizona or other states with plentiful solar or wind power — to help meet their own climate targets. Water in those regions is scarce. Meanwhile, areas where water is plentiful, such as in the East, have higher-carbon sources of power.
While supply and demand would suggest that this higher marginal cost of water would be reflected in the price, because of how government-regulated utility pricing works, facilities can avoid what should be an increased cost:
Eric Olson, Anne Grau and Taylor Tipton, “Data centers are draining resources in water-stressed communities” The regulated nature of water pricing often creates a situation where tech companies, such as those operating data centers, pay the same amount for water regardless of their consumption levels. This is because water rates are often set by public authorities based on factors like the cost of water treatment, distribution and infrastructure maintenance, rather than being determined by supply and demand in a competitive market.
As a result, tech companies may be able to negotiate favorable water rates or take advantage of pricing structures that do not fully reflect the marginal cost of their water consumption. This can lead to a lack of incentives for these companies to conserve water or invest in more efficient cooling technologies, as they may not face the full economic cost of their water use.
All of this applies to data centers as a general category, of which AI use is just a subset. But AI’s increased processing demand means an increased demand for data centers, which exacerbates this problem.
When it’s bad
The tests and comparisons in Part 1 show that AI is perfectly energy efficient at performing actual tasks for people. Every test I run shows that having a computer do a task instead of a human usually saves energy overall.
But there is still a problem. Data centers are using more water and electricity than they need to. AI can be efficient at tasks, but there are still a lot of ways to deploy AI tech that are not worth it. This waste overwhelmingly comes from systemic decisions stemming from bad incentives.
Land rush
The cost of AI use at any normal human scale doesn’t waste a problematic amount of energy. The problem is the astronomical cost of creating AI systems massive enough to ensure corporate dominance. Which, as a goal, is already bad, so spending any quantity of resources in pursuit of it is at least as bad as waste.
In my estimation the biggest and most fundamental energy problem in AI is the current land rush between tech companies to capture the market by creating the biggest and best AI. Even if we assume that the result of improved AI is a good thing, the current cost of competition in this space is astronomical.
Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and Policy Considerations for Deep Learning in NLP (Version 1). arXiv. https://doi.org/10.48550/ARXIV.1906.02243 …training a state-of-the-art model now requires substantial computational resources which demand considerable energy, along with the associated financial and environmental costs. Research and development of new models multiplies these costs by thousands of times by requiring retraining to experiment with model architectures and hyperparameters.
Likewise, the data sovereignty movement is aiming to scale these costs even higher by requiring intra-national data storage, and therefore prompting retraining.
Many companies are all trying to develop the same products: an everything app, a digital assistant, a text/image/audio/video content generator, etc. And they’re all doing it in the hopes that theirs is the only one that people will ever use. They actively want their competitors investment to not pay off, to become waste.
Models are trained speculatively but never used, because by the time they’re ready, they’re obsolete. The entire development cost becomes a write-off. Or, worse, expensive-to-train models are created as a proof-of-concept to fill out some american psycho type’s pitch deck in one meeting. The only value these create is pressure in intra-company politics.
And for the frontier models that are at the front of the race, the competitive advantage is to have more data points, more training expense. It’s the diminishing returns problem.
Google search
So, let’s talk about Bradley Brownell’s “Google AI Uses Enough Electricity In 1 Second To Charge 7 Electric Cars” headline.
With that out of the way, it’s true that Google AI uses enough electricity in one second to charge seven electric cars. More specifically, LLM interactions take 10 times more energy than a standard search, 3 Wh for LLMs compared to search’s 0.3 Wh:
de Vries, A. (2023). The growing energy footprint of artificial intelligence. Alphabet’s chairman indicated in February 2023 that interacting with an LLM could “likely cost 10 times more than a standard keyword search.” As a standard Google search reportedly uses 0.3 Wh of electricity, this suggests an electricity consumption of approximately 3 Wh per LLM interaction. This figure aligns with SemiAnalysis’ assessment of ChatGPT’s operating costs in early 2023, which estimated that ChatGPT responds to 195 million requests per day, requiring an estimated average electricity consumption of 564 MWh per day, or, at most, 2.9 Wh per request.
First, let’s go through the standard proportional cost thinking.
Set aside LLMs for a moment. Is being able to do a Google search valuable enough to justify the cost? I think obviously yes. It is an incredible public good that it exists at all, and the immediately valuable information it provides is worth the marginal cost it takes for the computer to run the query. 0.3 Wh per search is fine.
The next logical question is “is the AI answer 10 times as valuable?” And I think the answer is “not always.” But “not always” is exactly the part Google botched.
Wed Aug 14 20:35:31 +0000 2024It is so fucking annoying that any time I Google something, I now have to wait an extra few seconds for an AI to generate a completely irrelevant and incorrect answer that I have to scroll through to find the actual article I am looking for.


At time of writing, Google is prepending the results of most searches with an LLM-generated summary of what it thinks you want to know.
This is an escalation of what I decried two years ago in You can Google it. (Yes, I’m saying I called it.) Instead of the ten blue links, Google is trying to resolve every query using an algorithm for truth, which there is not one of.
But fundamentally, Google search is not supposed to be a truth generation machine. Imagine a black-box machine that answers questions you ask it correctly. Ignoring the fact that said machine can’t ever exist and it would be bad if it did, Google search is a fundamentally different product. Google search is a search engine. It is a tool to index and catalog the world’s information and deliver relevant, high-quality results to queries.
Single-truth LLM answers like the one Google’s AI delivers are the exact opposite: a hard step away from discovery and towards… something else.
There’s a good Ars piece (coincidentally also by Kyle Orland) that hits this point really well:
Kyle Orland, “Google’s AI Overviews misunderstand why people use Google” | Ars Technica Even when the system doesn’t give obviously wrong results, condensing search results into a neat, compact, AI-generated summary seems like a fundamental misunderstanding of how people use Google in the first place.
…
The value of Google has always been in pointing you to the places it thinks are likely to have good answers to those questions. But it’s still up to you, as a user, to figure out which of those sources is the most reliable and relevant to what you need at that moment.
…
One of the unseen strengths of Google’s search algorithm is that the user gets to decide which results are the best for them. As long as there’s something reliable and relevant in those first few pages of results, it doesn’t matter if the other links are “wrong” for that particular search or user.
…
Reputationally, there’s a subtle but important shift from Google saying, “Here’s a bunch of potential sources on the web that might have an answer for your search,” to saying, “Here is Google’s AI-generated answer for your search.”
In shifting away from indexing and discovery, Google is losing the benefits of being an indexing and discovery service.
But I’m here to talk about waste.
The user is in the best position to decide whether they need an AI or regular search, and so should be the one making that decision. Instead, Google is forcing the most expensive option on everyone in order to promote themselves, at an astronomical energy cost.
Once or twice I have found a Google AI answer useful, but both times it was because I was searching for something that I knew could be “averaged” from search results. The AI helped because I specifically wanted AI instead of search; it would’ve been better for there to just be a dedicated button for that.
If Google AI and Google search are fundamentally different products that do entirely different categories of things, you only need one or the other. All the computation time that goes into generating AI results to show someone who expressly told Google it wanted to search the index is automatically wasted. Bing, at least for now, gets this right: while there’s a flow from search to chat, querying its AI is a separate process on a separate page.
So Google has made a design decision that’s fundamentally wasteful of energy, and they’ve deployed this across the massive scale of Google search. Both design decisions are fundamentally irresponsible, but together the amount of waste multiplies to an absurd volume. 3 Wh for a useful answer is fine. 3 Wh per answer times 100,000 searches every second is catastrophically bad.
But it’s not just search: Google has started an initiative to run LLMs seemingly as much as possible:
Melissa Heikkilä, “Google is throwing generative AI at everything” | MIT Technology Review Billions of users will soon see Google’s latest AI language mode, PaLM 2, integrated into over 25 products like Maps, Docs, Gmail, Sheets, and the company’s chatbot, Bard. …
… “…We’re finding more and more places where we can integrate [AI language models’] into our existing products, and we’re also finding real opportunities to provide value to people in a bold but responsible way,” Zoubin Ghahramani, vice president of Google DeepMind, told MIT Technology Review.
“This moment for Google is really a moment where we are seeing the power of putting AI in people’s hands,” he says.
The hope, Ghahramani says, is that people will get so used to these tools that they will become an unremarkable part of day-to-day life.
With this updated suite of AI-powered products and features, Google is targeting not only individuals but also startups, developers, and companies that might be willing to pay for access to models, coding assistance, and enterprise software, says Shah.
“It’s very important for Google to be that one-stop shop,” he says.
It’s very important to Google for Google to be that one-stop shop, certainly. But it’s so important they’re willing to waste resources on ideas that can’t be expected to work, and that’s bad.
The lesson here is that AI is wasteful when its work goes unused, and it’s wasteful when it’s pushed on more people than will use it.
Overgeneral
Another mistake companies are making with their AI rollouts is over-generalization.
Because both training and inference costs scale with model complexity, any input data that goes unused in practice represents significant waste. To maximize energy efficiency, for any given problem, you should use the smallest tool that works.
In a way, this continues the pattern from beyond AI tools: more general tools with a larger possibility space are more expensive. In the same way AI tools are more expensive than high-performance software, general-purpose omni-model AI tools are more expensive than models tailored for a specific use.
This is a point I hadn’t considered with any depth myself, but Luccioni et al. found generality to be an extremely significant factor in energy cost, with unnecessarily general models using 14 times more energy than compact ones:
Power Hungry Processing: Watts Driving the Cost of AI Deployment? …this ambition of “generality” comes at a steep cost to the environment, given the amount of energy these systems require and the amount of carbon that they emit.
…We find that multi-purpose, generative architectures are orders of magnitude more expensive than task-specific systems for a variety of tasks, even when controlling for the number of model parameters. We conclude with a discussion around the current trend of deploying multi-purpose generative ML systems, and caution that their utility should be more intentionally weighed against increased costs in terms of energy and emissions.
4.2.1 Emissions of task-specific and multi-task architectures.
…there is a clear distinction between task-specific discriminative models (in blue), which have less emissions than both multi-purpose sequence-to-sequence (in yellow) and decoder-only generative models (in green). Given that the y axis in Figure 3 is in logarithmic scale, this indicates that the difference is several orders of magnitude, with the most efficient task-specific models emiting 0.3g of CO_2_eq per 1,000 inferences for extractive question answering on a dataset like SciQ, multi-purpose models emit 10g for the same task. This result follows intuitions derived from the model structures: while a task-specific model trained on binary text classification will carry out a softmax on a two-category vector to predict a class, a multi-purpose model will generate ‘positive’ or ‘negative’, which logically requires more energy because the prediction is based on the model’s entire vocabulary.
…task-specific models have a much more constrained decision space (e.g. two classes in the case of binary text classification), whereas multi-purpose models have a large output vocabulary to choose from, and are dependent upon the prompt schema and prompting strategy used.
…
Using multi-purpose models for discriminative tasks is more energy-intensive compared to task-specific models for these same tasks. This is especially the case for text classification (on IMDB, SST 2 and Rotten Tomatoes) and question answering (on SciQ, SQuAD v1 and v2), where the gap between task-specific and zero-shot models is particularly large, and less so for summarization (for CNN-Daily Mail, SamSUM and XSum). As can be seen in Table 4, the difference between multi-purpose models and task-specific models is amplified as the length of output gets longer.We find this last point to be the most compelling takeaway of our study, given the current paradigm shift away from smaller models finetuned for a specific task towards models that are meant to carry out a multitude of tasks at once, deployed to respond to a barrage of user queries in real time.
Unfortunately, there is indeed a paradigm shift away from finetuned models and toward giant, general-purpose AIs with incredibly vast possibility spaces.
For instance, to minimize power waste, you would never do this:
gpt-4o system card | OpenAI GPT-4o is an autoregressive omni model, which accepts as input any combination of text, audio, image, and video and generates any combination of text, audio, and image outputs. It’s trained end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network.
This “omni model” design that processes and outputs many different formats, with the ability to select between them as needed, is a very impressive display of ultra-generalized AI. But ultra-generalized AI is very often going to be the wrong choice for a category of tasks, and using more specifically scoped software would cumulatively save a significant amount of energy.
Irresponsible infrastructure
Texas is in the middle of a years-long economic campaign to attract data centers by signing datacenter-friendly policies into law. This notably ramped up in 2020 with a pro-data center push specifically focused around attracting blockchain mining facilities:
Representative Tan Parker: [Texas has] now set our sights on becoming the jurisdiction of choice for investors, entrepreneurs, and enterprises to build and deploy blockchain technologies applications and other emerging tech innovations.
William Szamosszegi, Sazmining CEO: There’s less red tape around crypto and crypto mining in Texas, which means there are fewer barriers to entry and higher overall crypto acceptance, making it easier for miners to operate. … The more favorable regulatory environment in Texas makes it the ideal state to launch these kinds of operations.
Lee Bratcher, Texas Blockchain Council president: Texas is poised to become the jurisdiction of choice for bitcoin, blockchain, and digital asset innovation
Lee Bratcher, Texas Blockchain Council president: This is clearly the next race for innovation. Just as Texas played an outsized role in helping the U.S. win the space race, Texas elected officials, state agencies, business, universities and entrepreneurs are teaming up to put a man on the moon in the race for dominance in blockchain innovation and the coming internet of value.
Mike Orcutt, How Texas’s wind boom has spawned a Bitcoin mining rush Leading mining chip maker Bitmain, which is based in China, has also moved into Texas, opening a facility with 50 MW of power in a town called Rockdale in October that it says can eventually scale up to 300 MW. A third big player, a German firm called Northern data, says it plans to build the largest mining facility in the world, also in Rockdale, which it says will devote a full gigawatt (1,000 MW) to cryptocurrency prospecting. … These are just the most high-profile mining operations laying claim to the Lone Star State. A number of other firms are either planning (or rumored to be planning) to set up facilities there, all chasing inexpensive power.
Then there’s another factor, which likely appeals similarly to miners as it does to electricity producers: Texas’s electricity market is deregulated. …big electricity consumers like Bitcoin mines can negotiate power purchase agreements—contracts that stipulate that they will buy power at a certain price for a certain amount of time—directly with electricity producers, instead of having to deal with intermediaries like utilities. That can be great for businesses trying to keep their energy costs low, says Rhodes.
Unfortunately, Texas is a very bad place to do this. Texas is an arid, drought-prone environment, and it often can’t afford to spend water on industrial, non-safety-critical uses. Worse than that, though, is the impact on the power grid. Texas’s power grid is under-regulated and poorly-maintained, leading to major failures in power availability. Its independent infrastructure is also disconnected from the rest of the nation, meaning there isn’t a mechanism to import power if the grid is over-capacity. An already-strained power grid like Texas’ is the worst place to see explosive, unpredictable growth in power demand.
But Texas’ government has put all its momentum into attracting data centers, which has invited that explosive growth in demand. Now that they’re seeing the infrastructure problem, they aren’t equipped to reverse course and moderate the growth as needed.
AI could strain Texas power grid this summer | KERA News (2024) “How many are coming? That’s still TBD, but we know that they are explosively growing,” ERCOT CEO Pablo Vegas told lawmakers in one of two hearings this month at the state capitol.
…
“How do we build enough infrastructure to accommodate a new city popping up in six months, with effectively no notice?” [Doug Lewin, who publishes the Texas Energy and Power Newsletter] asks.The answer: maybe you don’t.
…
At a recent ERCOT board of directors meeting, Dan Woodfin, the group’s vice president of system operations, said the inability to forecast energy use by cryptomines and similar big power consumers was “the most worrisome thing” going into this summer.
…
Texas is no stranger to power grid anxiety. Between the heat that’s only getting hotter, an aging fleet of power plants, and the challenges of integrating renewable energy, the system is fragile.Now, a boom in energy-hungry computer data centers is adding a new element of risk this summer. … ERCOT puts the chance of rolling blackouts at around 12% in August.
“We cannot build the grid fast enough to keep up with demand… Even before we had every damned crypto and data center … move to Texas,” Alison Silverstein, a consultant and former state and federal energy official, told KUT.
When a federal inquiry tried to probe Texas’s infrastructure policy, Texas doubled-down on their support for data businesses. These problems were anticipated, and shouldn’t have represented a sudden need to change momentum; it was the legislative anti-regulatory culture that was dangerously wrong.
I’ve focused on Texas here, but similar problems are also plaguing Arizona and Virginia.
This is a perfect example of externalizing risk. Building new data centers primarily benefits the data companies and the tax-collecting government. But putting additional strain on the power grid risks state-wide brownouts and power rationing that will harm everyone. Privatized profit, socialized risk.
Waste
We know that AI is energy-efficient at performing actual tasks. And yet we’re seeing the AI rollout come with a significant resource cost, but without any particular increases to productivity or quality of life. How did we get from that to this? Fundamentally, waste, on an unimaginable scale.
What happens when the utility goes toward zero? The proportional cost — the amount of resources spent in order to gain a benefit — approaches infinity, because there was no benefit.
Waste is the killer problem.
Even if there were more efficient methods available, the bulk of waste does not come from inefficiency, it comes from doing work that should not be done at all. If you’re seeing something useful happening at all, that’s not part of the bulk of the problem. The real body of the problem is pouring enormous amounts of resources into worthless products and failed speculation.
The subtitle for that bloomberg article is “AI’s Insatiable Need for Energy Is Straining Global Power Grids”, which bothers me the more I think about it. It’s simply not true that the technology behind AI is particularly energy-intensive. The technology isn’t insatiable, the corporations deploying it are. The thing with an insatiable appetite for growth at all cost is unregulated capitalism.
So the lesson is to only do things if they’re worthwhile, and not to be intentionally wasteful. That’s the problem. It’s not novel and it’s not unique to AI. It’s the same simple incentive problem that we see so often.
Blame shifting
Given this, it seems like there’s a lot of misplaced anger towards individual users of AI services. Individual users are — empirically — not being irresponsible or wasteful just by using AI. It is wrong to treat AI use as a categorical moral failing, especially when there are people responsible for AI waste, and they’re not the users. The blame for these problems falls squarely on the shoulders of the people responsible for managing systems at scale. Using ChatGPT doesn’t tip that scale. You can’t get mad at people who are being responsible as reaction to other people who are not.
And yet visible individuals who aren’t responsible for the problems are being blamed for the harm caused by massive corporations in the background.
In a perverse way, data companies are actually incentivized to encourage this anger about individuals using AI, because it removes moves the focus from their substantial contribution to the problem to an insubstantial one they’re not directly responsible for.
It’s the same blame-shifting propaganda we see in recycling, individual carbon footprints, etc.
Monorail!
The problem isn’t the tech, it’s the arms race. The tech isn’t inefficient at what it does. Individual consumer choices are not what’s impacting the environment.
Remember the monorail metaphor I opened part 1 with? I think that’s actually a very useful analogy.
The joke is that Springfield is wildly unsuited for a monorail. It’s a solution that doesn’t fit the problem, and it’s only being sold as a con job. But that doesn’t automatically generalize to condemning the machine itself. A monorail can be a sensible solution in appropriate cases, and the absurdity of a monorail in Springfield is not a good argument against trains in general. It works when it’s there to be useful. It breaks when it’s only there to make money.
There are a lot of people trying to sell AI as a con job right now. That doesn’t mean it’s always the wrong thing, it just means you can’t trust the salesman.
Do things that are worthwhile!
Related Reading
-
In fact, air conditioning actually uses more water than water-cooling, so just because “water” is in the name doesn’t mean that’s the cost. ↩
-
This is not the only geographic factor though; data centers are also best built in areas with network infrastructure and close to the population centers they serve, for instance. ↩
-
Li, P., Yang, J., Islam, M. A., & Ren, S. (2023). Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models (Version 3). arXiv. https://doi.org/10.48550/ARXIV.2304.03271 estimates a total “water consumption footprint” of ~3.7 L/kWh. This is significantly higher than my 1 L/kWh estimate, which is because the linked study is summing the Water Usage Effectiveness (water used per operation) with the “Electricity Water Intensity”, the amount of water used in the generation of the power used. This is a worthwhile metric, but it’s not relevant here, because the costs of producing the power are included with our analysis of energy efficiency; counting both the resources used to generate the energy and the energy itself as a resource would be double-counting. ↩