Identity Verification is as Bad as It Can Be
Identity Verification is as Bad as It Can Be
This is an addendum to OS-Level Age Attestation is the Good One, where I talk about the potential of legal standards for age attestation as an alternative to age verification. Not already convinced of the dangers of age verification? The extent of the evil waiting behind identification systems and deanonymization is unspeakably vast, and fortunately it’s getting extensive coverage. Here’s a quick look to get you up to speed.
Direct digital censorship
A lot of the energy behind age verification comes from authoritarians eager to censor political dissent, promote propaganda and retaliate against critics. This is a power grab, with bills designed to seize power over specific content the government objects to:
Thu Mar 05 15:06:26 +0000 2026This House E&C Markup is off to a "saying the quiet part out loud" start, with the Chairman saying outright "algorithms amplify addictive, harmful content."
It is always, 100% of the time, about content. And that's why these bills continue to be unconstitutional.

Thu Mar 05 15:24:35 +0000 2026"These platforms are engineered to capture kids' attention"
I hate to break it to Congress, but that's literally the point of all media. "Creating media that people want to keep consuming" is not a standard workable under the First Amendment.
Thu Mar 05 15:48:31 +0000 2026@AOC Here's the problem: the FTC can just decide that whatever content it doesn't like is harming children, and find some way that platforms aren't acting "reasonably" to prevent it.
And it will.
Governments are, of course, trying to claim control over “public discourse”. Like all seizing of arbitrary power, the risks associated with this are volatile and unbounded, because they depend on who holds power at any given moment in a political system where power is expected to rotate.
Discord
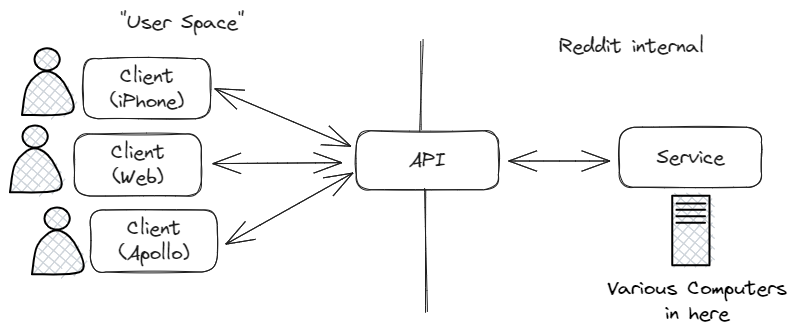
As a case study, let’s take a look at one of the latest major services to attempt age verification: Discord. At time of writing, Discord is in the process of trying to switch to a “Teen Default” system, where every user is assumed to be a minor unless they can prove their age to Discord. Discord is a communications platform used widely by adults, and during COVID Discord very intentionally expanded their market domain beyond gaming to focus on being a global platform, so the assumption that all spaces are for kids is clearly incorrect.1 But Discord is sometimes used by children, and since it’s a communications platform people can use it to communicate horrible things. Boomers have learned they can be insane about this, so Discord is under significant pressure to balance its goal of being a universal communications platform with child safety.
 Monorail!
Monorail!