 What Was The Beginner's Guide About?
What Was The Beginner's Guide About?
- 41 min read (1+ hr w/ quotes)
- Posted in literature
What Was The Beginner's Guide About?
 What Happened With Homestuck? (Recap)
What Happened With Homestuck? (Recap)
It’s been eight months since what I’ve jokingly called my Homestuck Divorce. I published The Unofficial Homestuck Collection Takedown and The Homestuck Union Was Always Fake explaining everything, but they’re very long. I think I did need to be thorough in documenting those details, but the information that’s relevant to most people is hard to consume. People kept asking me to summarize and I’d rather just have this out there so I don’t have to think about it again. I don’t want to have to come back to Homestuck, so this is a tl;dr retrospective summary to organize my thoughts and capture this question that still keeps coming up: “what happened?”
 Identity Verification is as Bad as It Can Be
Identity Verification is as Bad as It Can Be
This is an addendum to OS-Level Age Attestation is the Good One, where I talk about the potential of legal standards for age attestation as an alternative to age verification. Not already convinced of the dangers of age verification? The extent of the evil waiting behind identification systems and deanonymization is unspeakably vast, and fortunately it’s getting extensive coverage. Here’s a quick look to get you up to speed.
A lot of the energy behind age verification comes from authoritarians eager to censor political dissent, promote propaganda and retaliate against critics. This is a power grab, with bills designed to seize power over specific content the government objects to:
Thu Mar 05 15:06:26 +0000 2026This House E&C Markup is off to a "saying the quiet part out loud" start, with the Chairman saying outright "algorithms amplify addictive, harmful content."
It is always, 100% of the time, about content. And that's why these bills continue to be unconstitutional.
Thu Mar 05 15:24:35 +0000 2026"These platforms are engineered to capture kids' attention"
I hate to break it to Congress, but that's literally the point of all media. "Creating media that people want to keep consuming" is not a standard workable under the First Amendment.
Thu Mar 05 15:48:31 +0000 2026@AOC Here's the problem: the FTC can just decide that whatever content it doesn't like is harming children, and find some way that platforms aren't acting "reasonably" to prevent it.
And it will.
Governments are, of course, trying to claim control over “public discourse”. Like all seizing of arbitrary power, the risks associated with this are volatile and unbounded, because they depend on who holds power at any given moment in a political system where power is expected to rotate.
As a case study, let’s take a look at one of the latest major services to attempt age verification: Discord. At time of writing, Discord is in the process of trying to switch to a “Teen Default” system, where every user is assumed to be a minor unless they can prove their age to Discord. Discord is a communications platform used widely by adults, and during COVID Discord very intentionally expanded their market domain beyond gaming to focus on being a global platform, so the assumption that all spaces are for kids is clearly incorrect.1 But Discord is sometimes used by children, and since it’s a communications platform people can use it to communicate horrible things. Boomers have learned they can be insane about this, so Discord is under significant pressure to balance its goal of being a universal communications platform with child safety.
OS-Level Age Attestation is the Good One
There’s a coordinated effort to use the “child safety” euphemism to cripple the internet with identity verification mandates. That’s bad. But buried in the mix there’s a genuinely good idea with enough political capital that it might stick around and do some good.
Every time I’ve tried to write an article on the topic of child internet safety my energy has fizzled into depression, because as one researches the topic it becomes obvious that everyone with any relevant power is refusing to solve the problem on purpose. It’s demoralizing and it’s been mostly useless for me to do any thought work in this area.
But California’s age attestation bill might be an exception to this. Because it’s age attestation, not age verification, it looks like a significant political step in the right direction, and with the right focus it could do a lot of good. A lot of people have (fairly!) assumed attestation was age verification or at least lays the groundwork, but I think this isn’t the case. There is always the danger of future bad legislation, but OS attestation doesn’t pave the way for it, it provides a strong defense against it. We need a good idea to win the child safety war, not because we’re in dire need of more online child safety, but because addressing the real concerns correctly blocks a whole slew of impossibly dangerous policies.
My ideal age filtering tool is a system of client attestation with trust rooted in the adult administrator, provided by an OS-level API provided as preemptive verification, enforced by compliant browsers and application stores. And we’re shockingly close to that.
People on the privacy side of the age verification war — my side — will argue that parents already have everything they need for comprehensive web filtering if they want to use it. I think this isn’t quite true; there’s one notable architectural gap that a technical solution could meaningfully fill.
There are many existing content filtering tools geared toward child safety but their weakness is that they’re reactive. Traffic filters can identify and block traffic from known websites and on-device content filters can try to detect and block specific content. But this requires the user reacting and defending against every possible source and behavior. It’s the same cat-and-mouse game as adblockers. And like adblockers, the more closed down the system is — like iOS or gaming consoles — the harder it is for developers to make exactly the right product.
The internet sometimes assumes minors are supervised — since they have parental consent to have the device in the first place — but this often isn’t the case. It’s very common for minors to have their own phones or tablets with unsupervised access. When they’re online or downloading apps, they’re not sitting with a parent, they’re unsupervised, roaming children. Parents are dropping their kids off in the city.
This isn’t inherently bad; it seems like parents and children both want children to be able to exist independently without granular supervision, and so there’s a desire to make that situation safer. That shouldn’t come at the cost of any adult liberty or even the liberty of children with parental consent; it just means we want an ecosystem that allows for unsupervised children to exist within it.
Right now the burden is on parents to be active defenders protecting their children from a vast ecosystem of companies investing research and capital into optimizing how efficiently they can exploit money and data out of everyone in the world. It would be a meaningful improvement if there were a safe way to prevent some of this exploitation by putting reasonable requirements on providers, so long as this can be done in a way that doesn’t cause more problems.
But the lack of a perfect parental control system isn’t the main problem here. The real danger is the push for online identity verification using child safety as a justification.
Smart and privacy conscious people demand “No age verification” (quite reasonably!), but that doesn’t offer the quick fix people are looking for. More importantly, it doesn’t relieve the political pressure and so doesn’t take away the excuses of tyrants.
Normally “do nothing” would be the safest option here, but the danger of uninformed and reactionary voters means there is a great deal to gain by satisfying the concerns safely instead of letting the solution be evil. A technical standard for parents to somehow identify their children as children is the relief valve for dangerous political pressure. This doesn’t appease the fascists and censors. This doesn’t cede them any ground and it’d be wrong to try to; there’s no satisfying that hunger and it’s a dangerous mistake to feed it. What it does is actually improve the material conditions for the people they’re trying to trick.
A proactive system that puts some of the burden for protecting children on those companies is a real relief to this, and it would be a meaningful improvement if something could address this without causing bigger problems.
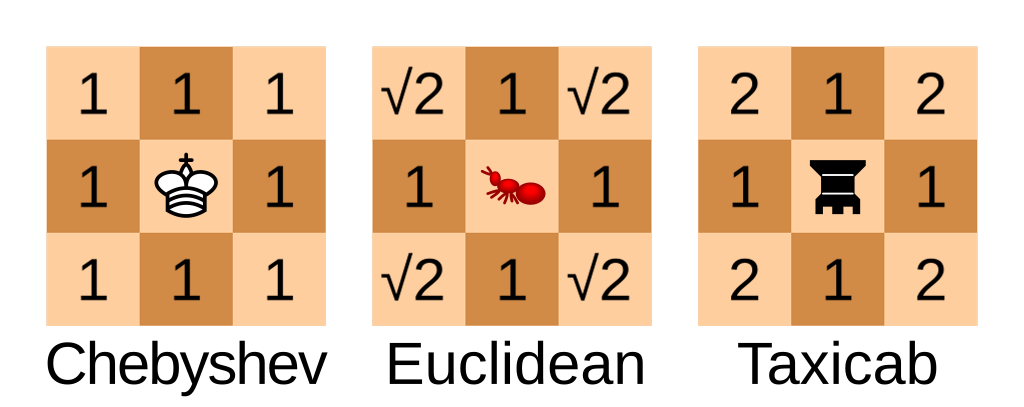
There are three basic categories of age filtering: nothing, client attestation, and client verification. These provide services varying levels of confidence in their knowledge of users. (It’s tempting to simplify confidence to labels like “strong” or “weak” but it’s important to think about what’s actually being secured, and from who.) Different people call these different things, but here’s my taxonomy with the labels I’ll use.
Interloper and Artistry in Impressionistic Horror
Interloper is an unfiction ARG series for source nerds. It feels like Interloper was laser-targeted to drive me specifically insane, but it turns out that was true for a lot of people. After three years the first episode has 856k views, and the recently released final episode is a feature-length 1:54 film that earns its runtime.
I’ve been obsessing about Interloper since the beginning, and when I saw the finale I knew I had to finish it out properly. But this article is my third attempt to write something about Interloper, after spending several weeks just doing research.
My first instinct after seeing the finale was to “solve” it. There was an enormous amount of information available that was all interconnected and painted a picture of this huge, fascinating world. Interloper F didn’t answer all the questions the series asked, but surely with all the clues it gave us, someone who really understood the series would put the pieces together. Surely I could, if I gave it some time and attention.
But that didn’t work.
Fandom and The Freedom Motif
Fandom is the most important thing in the modern media industry. Fans buy the products and advertise the brand, but are also the primary source of feedback. The media is what the community forms around, but the community is what feeds the media.
But the relationship between a work’s copyright holder and its fan community is structurally antagonistic. The IP holder and members of the fan community have fundamentally different interests which sometimes align but sometimes don’t. The rightsholder depends on the goodwill of the fandom, but at the same time there is always danger of the community being attacked by the rightsholder. The law creates an implicit hovering threat of legal violence, and the profit motive encourages bad actors to pull the trigger. This doesn’t mean the relationship has to be antagonistic in practice, but it means there is always an underlying potential for conflict that has to be reasoned with. The threat is always there.
There is a productive tension here. Fanwork can serve functions official work can’t, and the community surrounding a work is one of the main things that gives a work “value”, in a base economic sense. They’re the ones buying the products. Media companies are desperate to have more fans because that directly translates into their ability to make money.
Likewise, the health of the franchise matters to the people who love it, and official recognition of fan communities can be a good thing.1 Fan work can be elevated, talented creators can be brought on as part of official projects, etc. Official recognition can serve as a badge of honor and help platform and encourage talent and creativity in the community.2
But the deciding factor in whether the creator/fan relationship is healthy or exploitative is whether the community is allowed to be independent. It’s fine for official spaces — fourms, Discord servers, etc. — to exist, so long as the purpose isn’t to capture and enclose a community. Media and fandom can have a symbiotic relationship, but as soon as the corporation tries to exercise control over their fans, it turns into an ugly hostility.
 Graph Paper Lindenmeyer Systems
Graph Paper Lindenmeyer Systems
When I was a kid I learned about Lindenmeyer Systems and the fun tree patterns they create. I even followed a Twitter bot that generated and posted random pretty lsystem renders.
These are similar to fractals, except unlike traditional fractals they don’t usually expand within a fixed space, they either continue to grow or loop back intersecting themselves.
Meanwhile I spent most of my time in school and needed something to occupy my hands with. I did a lot of notebook doodling, except people notice those. But I did have graph paper. And graph paper gives you enough structure to draw lsystems by hand. So I did, a lot.

I probably went through a notebook every two years, and I can’t remember once ever drawing an actual graph. This was when I was a child in childish ways and hadn’t yet learned about dot paper. Oh, misspent youth....
There are a couple interesting things about this mathematically.
First, there’s only really one interesting space-filling pattern to draw on graph paper, which is forking off in two 45 degree angles. Anything that doesn’t fit on the coordinate grid (like incrementally decreasing line lengths) becomes irregular very quickly. The main option to play with different patterns is by setting different starting conditions. (Seems like it’d get boring quick, right? I spent the rest of the time trying to apply the Four color theorem in an aesthetically satisfying way. Still haven’t solved that one.)
Second, drawing on a coordinate grid means using Chebyshev Geometry, where straight lines and diagonal lines are considered the same length. So a circle (points equally far apart from a center point) is a square. This is also sometimes called chessboard geometry, because it’s how pieces move on a grid.
Also, because I’m drawing this by hand, I can only keep track of visible tips. So if tips collide I count them as “resolved”, even if mathmatically they’d pass through each other.
But I kept hitting the end of the graph paper.
I was bored in a work meeting this week and ended up doing the same thing, and it made me wonder about the properties of the pattern. Did it repeat? Did it reach points of symmetry? I thought it would be fun to whip up a tool to run my by-hand algorithm to see.
There are lots of web toys for lsystems but none are designed with these graph paper constraints. So just as an exercise I built my own from scratch, and it’s pretty good at drawing my high-school pattern.

The answer to the pattern question is: it depends on the starting position! If you start with one line you start to see radial symmetry, but if you start with two lines facing away from each other (as in the animation) it’s more interesting. Neat.
Each generation is considered a state frame that keeps track of lines (for rendering), buds (for growing the next iteration), bloomed_buds (for bud collision) and squares (for line collision).
For the Chebyshev geometry I just keep every line at a 1.0 length and let the trigonometry functions round up.
I didn’t actually implement a parser for formal Lindenmeyer syntax, I just defined everything recursively in pure Javascript, using a definition to encapsulate details about the pattern:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Then rendering is done recursively:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
There’s a slight complication to doing this cheaply with lines: on paper, there are cases where lines intersect, and in those cases I stop at walls, even if it means drawing a partial line. Doing that kind of collision detection here in vector space would be very complicated! And without it the pattern loops back on itself and doesn’t look as good, and definitely doesn’t match my notebooks:
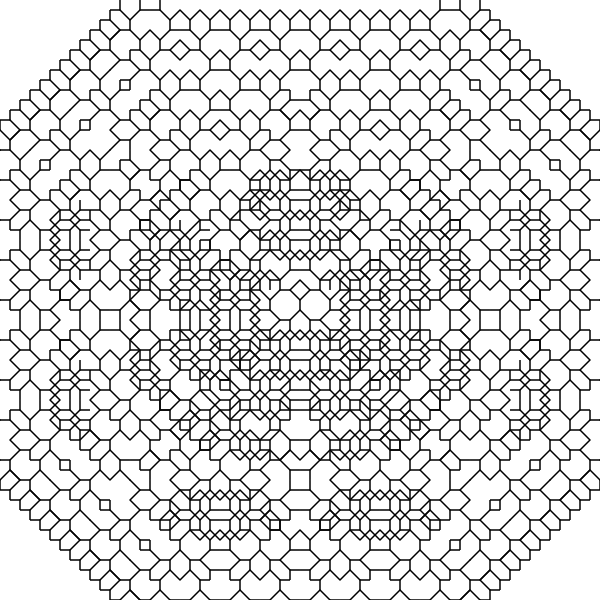
The solution for this was very simple collision detection. The final program keeps tracks of which squares are “occupied” and breaks branches any time they’d collide.
I uploaded it to my stash if you want to play with it. As an added constraint I wrote everything by hand in one single-file html page.
The one problem with the tool (besides being bare-bones) is it renders the output as an SVG instead of a bitmap on a canvas. This “feels right”: they’re lines, might as well make them vectors. But on high values browsers have performance issues rendering very large quantities of DOM elements.
I’d rewrite the renderer to draw to a canvas instead except I like the idea of the infinite SVG canvas specifically. The point was to escape the edges of the graph paper, remember?
But I’d already abstracted line drawing so the line coordinates were stored in state frames, so it was easy to write an alternate renderer using the canvas API.
https://stash.giovanh.com/toys/lsys.html
Illustration by Cmglee - Own work, CC BY-SA 4.0, Link ↩
 a wholesome plane has hit the second cozy tower
a wholesome plane has hit the second cozy tower
Here’s an advertisement I got from a game company named Rogue Duck Interactive.
Thu Aug 28 05:05:07 +0000 2025Start your cozy airport security job!👮🏻♂️
Weigh and scan bags, ask passengers questions, and if you are not convinced, search their luggage for dangerous items.
Wishlist on Steam!

The game they’re advertising here — which they neglect to name outside the screenshot — is “Nothing to Declare.”1 And it caught my eye, because there’s problems.
If you’ve been living under a rock for the last ten years you might not recognize this as the gameplay from Papers, Please.
Papers, Please (2013), of course, is the multi-million-selling dystopian bureaucracy simulator game where you work as an immigration enforcement officer for a despotic regime.
Papers is known as one of the games of all time. It uses the mechanics of rote bureaucracy — checking correctness of paperwork, matching dates, enforcing documentation requirements — to connect the player to a cruel and miserable world. The message and mechanics perfectly intertwine: the dystopia is entwined with the nature of the policing, which is both the setting and the game mechanic.
It’s an intense, profound piece that prompts the player to think about the way political structures affect real human lives. It prompts introspection about the role and agency of the individual within a system and how morality responds when someone is faced with a hard reality: a political and economic moment where harming others for profit may be the only way to feed your own family. Papers is “video games as true art”, “brilliantly written”, “grim yet affecting”.
Rogue Duck hasn’t been living under a rock. They know their game “takes inspo” from Papers, Please, but it has its own “original take and ideas.”
Sun Sep 07 02:51:36 +0000 2025@sensdertale Team definitely likes and takes inspo from Papers, Please. But I think both games can exist together, and I guarantee we will have our own original take and ideas in it.
Now, I don’t care that Rogue Duck is iterating on Papers. What’s hooked me here is this original take they’re so excited about. Because Declare is more than a shameless clone: it has its own identity and it does have something to say. Nothing to Declare comes on stage following Papers, turns to the audience, and what it has to say is: “man, that guy was a downer, am I right?”
That fun new original idea Rogue Duck adds to the equation is that now the bureaucracy of immigration is fluffy and wholesome. A fun little action parallel to making postcards and pouring coffee.
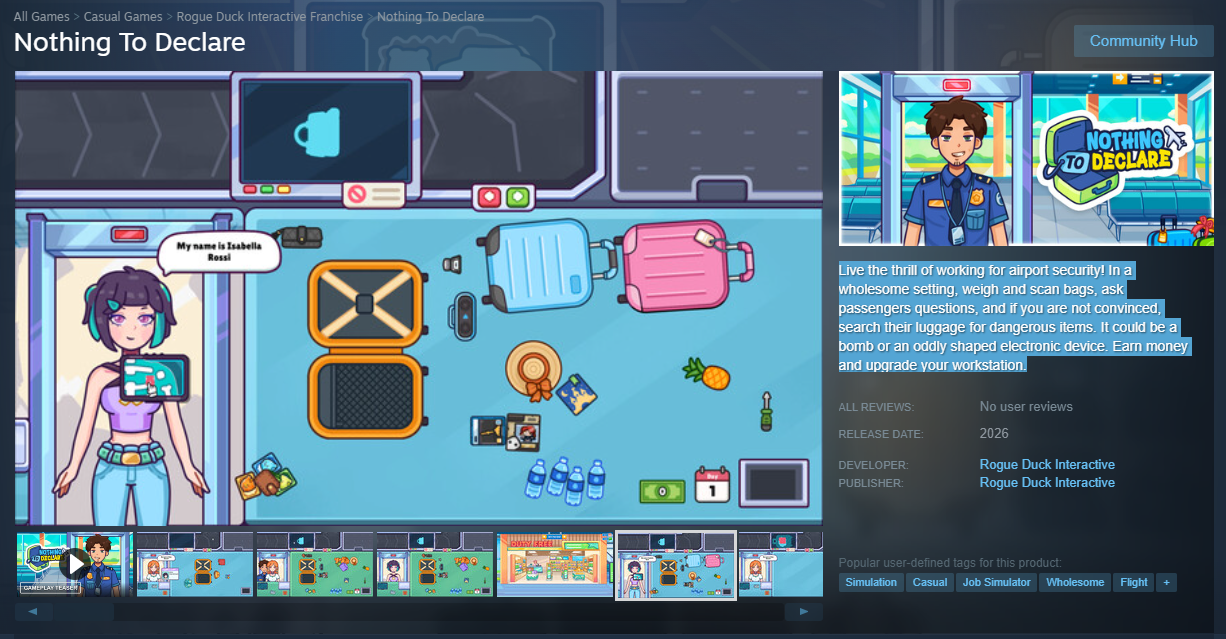
This isn’t even an interpretation, they shoehorn it right in their store description.
A Hack is Not Enough
Recently we’ve seen sweeping attempts to censor the internet. The UK’s “Online Safety Act” imposes sweeping restrictions on speech and expression. It’s disguised a child safety measure, but its true purpose is (avowedly!) intentional control over “services that have a significant influence over public discourse”. And similar trends threaten the US, especially as lawmakers race to more aggressively categorize more speech as broadly harmful.
A common response to these restrictions has been to dismiss them as unenforceable: that’s not how the internet works, governments are foolish for thinking they can do this, and you can just use a VPN to get around crude attempts at content blocking.
But this “just use a workaround” dismissal is a dangerous, reductive mistake. Even if you can easily defeat an attempt to impose a restriction right now, you can’t take that for granted.
There is a tendency, especially among technically competent people, to use the ability to work around a requirement as an excuse to avoid dealing with it. When there is a political push to enforce a particular pattern of behavior — discourage or ban something, or make something socially unacceptable — there is an instinct for clever people with workarounds to respond with “you can just use my workaround”.
I see this a lot, in a lot of different forms:
The Homestuck Union Was Always Fake
The Homestuck Independent Creative Union was announced in October 2023, claiming itself to be a “union” of creators working on Homestuck associated projects. The main selling point of this organization is that it was fully independent of Homestuck, Inc., Andrew Hussie, or any of the other existing management structures that were, at this point, known to be unsound. But all of this was untrue from day one. The HICU was never a union and it was never independent of Andrew. In fact Andrew doesn’t just have theoretical authority, they’re actively wielding power over projects in secret.
I want to give a very important disclaimer for this “anti-HICU” looking article because I really, really don’t want to see blame misplaced because of this. I think when most people familiar with it think of the HICU, the reaction is “oh, they’re doing better” or even “yeah, I’m on their side.” I don’t fault you for this! Based on what they said about themselves many people — including me personally — gave the HICU a huge amount of good credit upfront, and they’ve done very little publicly to hurt that image. So if you’re an HICU person — if you’re with FRAF, or DCRC, or even Beyond Canon — I am not attacking you with this! I am not against your “side.” The problem here is not the creatives, it’s strictly management. Whether you’re a fan or someone trying to work with the union, you are the one at risk here and I want to help you most of all.
Around October 2023 Andrew Hussie “restructured” Homestuck’s publishing agreement with Viz Media in order to reestablish their “control over the brand.” Homestuck then announced the relaunch of Homestuck^2: Beyond Canon, run by the also newly-announced Homestuck Independent Creative Union.


{kind=link}
{kind=link}
{kind=link}