 cyber
cyberThe other day I had a quick medical question (“if I don’t rinse my mouth out enough at night will I die”), so I googled the topic as I was going to bed. Google showed a couple search results, but it also showed Answers in a little dedicated capsule. This was right on the heels of the Yahoo Answers shutdown, so I poked around to see what Google’s answers were like. And those… went in an unexpected direction.
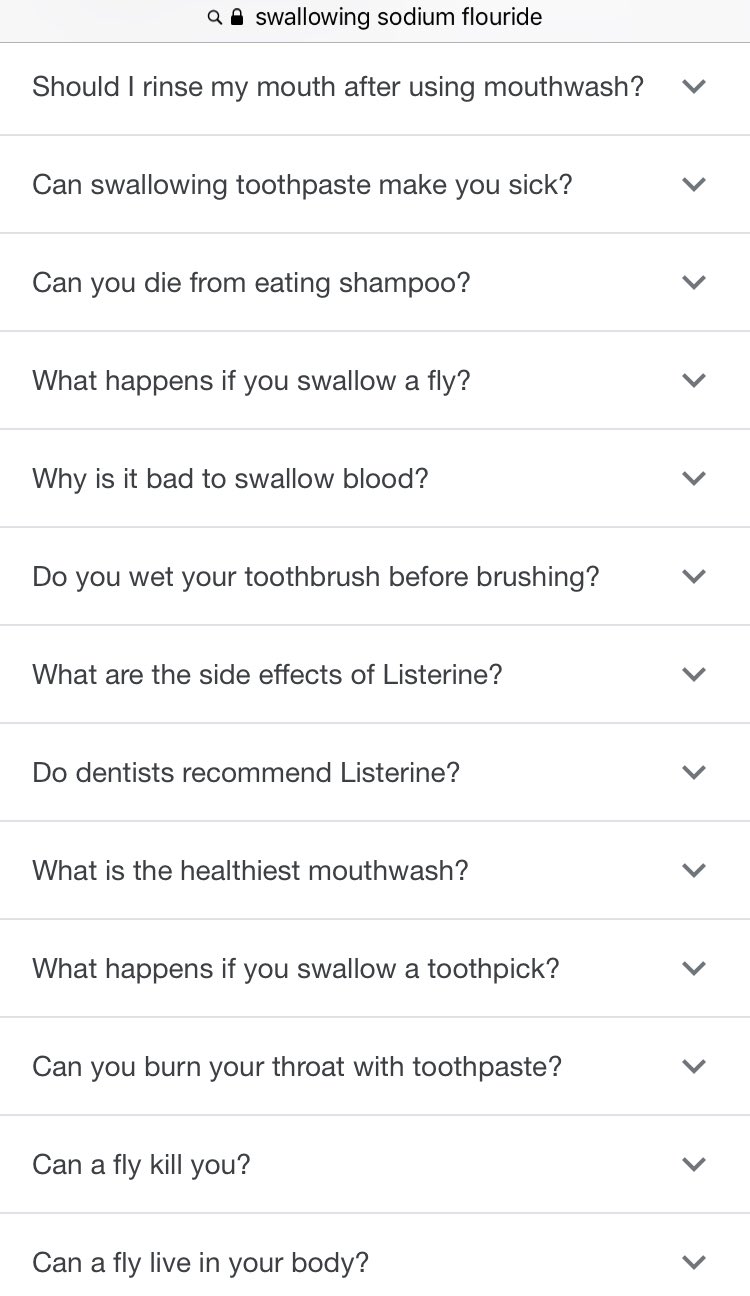
Replying to giovan_h:Fri Feb 26 07:40:22 +0000 2021me: so should I induce vomiting or
google: here’s how and why to drink human blood



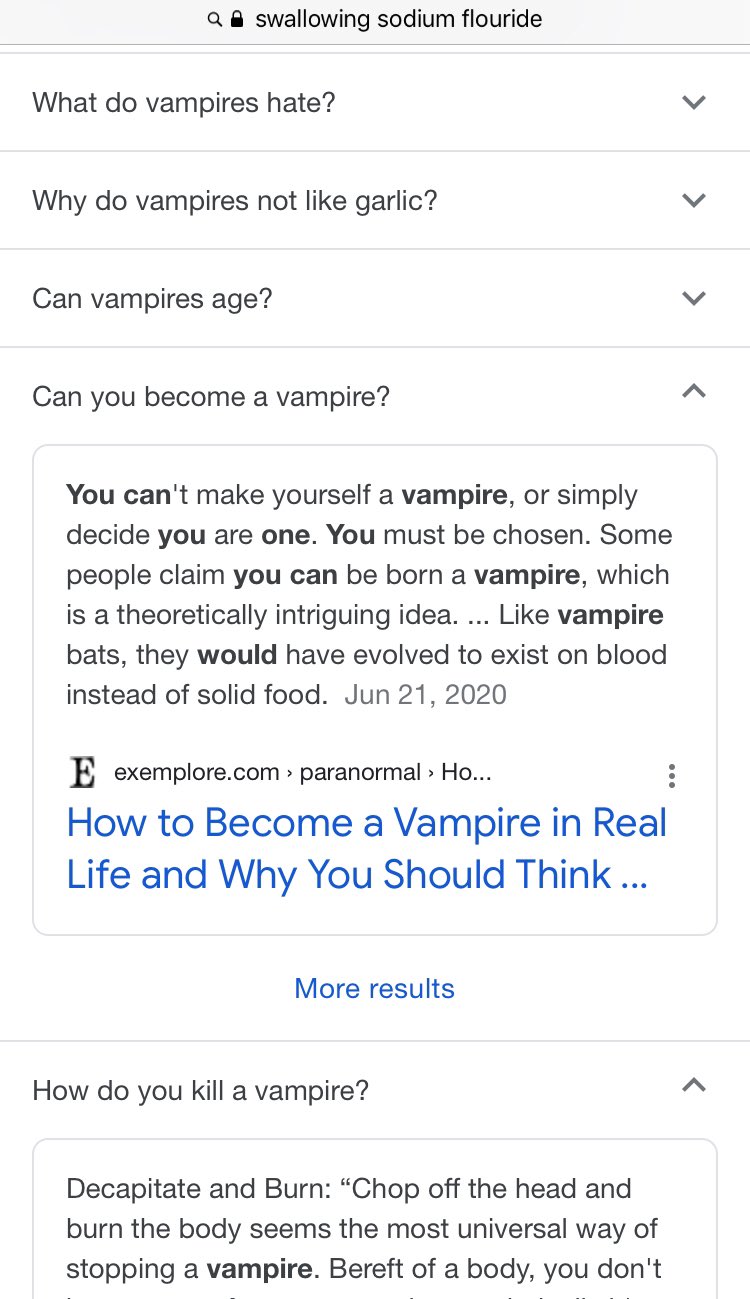
So, Google went down a little rabbit trail. Obviously these answers were scraped from the web, and included sources like exemplore.com/paranormal/ which is, apparently, a Wiccan resource for information that is “astrological, metaphysical, or paranormal in nature.” So possibly not the best place to go for medical advice. (If you missed it, the context clue for that one was the guide on vampire killing.)
There are lots of funny little stories like this where some AI misunderstood a question. Like this case where a porn parody got mixed in the bio for a fictional character, or that time novelist John Boyne used Google and accidently wrote a video recipe into his book. (And yes, it was a Google snippet.) These are always good for a laugh.
Sat Apr 27 10:36:51 +0000 2019thanks google


Tue Jan 17 18:04:08 +0000 2017honestly this is still my favourite AI misunderstanding


The Google search summary vs the actual page
— insomnia club (@soft) October 16, 2021
Wait, what’s that? That last one wasn’t funny, you say? Did we just run face-first toward the cold brick wall of reality, where bad information means people die?
Well, sorry. Because it’s not the first time Google gave out fatal advice, nor the last. Nor is there any end in sight. Whoops!
The Semantic Search
So, quick background.
These direct query responses — a kind of semantic search — are what Google calls Featured Snippets. Compared to traditional indexing, semantic search is actually a relative newcomer to web search technology.
In 2009 Wolfram launched Wolfram|Alpha, a website that, instead of searching indexed web pages, promised to answer plain-english queries with computational knowledge: real, scientific data backed by scientific sources.
Wolfram was a pioneer in the field, but other companies were quick to see the value in what Semantic Search, or we might now call responses. Right on the heels of Wolfram|Alpha, Microsoft replaced Live Search with Bing.com, which was what they called a “Decision Engine.” In the 2009 Bing.com press release, CEO Steve Ballmer describes the motivation behind the focus on direct responses:
Today, search engines do a decent job of helping people navigate the Web and find information, but they don’t do a very good job of enabling people to use the information they find. … Bing is an important first step forward in our long-term effort to deliver innovations in search that enable people to find information quickly and use the information they’ve found to accomplish tasks and make smart decisions.
Today, Google has this video showing the evolution of the search engine, starting with the original logo and a plain index of websites, and ending with a modern-day search page, complete with contextual elements like photos, locations, user reviews, and definitions. You know, what we’re familiar with today.
Google describes its goal for search as being to “deliver the most relevant and reliable information available” and to “make [the world’s information] universally accessible and useful”. Google is particularly proud of featured snippets and responses, and paraded them out in Hashtag Search On 21’:
One contradiction stands out to me here: at 00:45, a Google spokesperson uses “traffic Google sent to the open web” as a metric Google is proud of. But, of course, featured snippets are a step away from that; they answer questions quickly, negating the need for someone to visit a site, and instead keeping them on a Google-controlled page. This has been a trend with new Google tech, the most obvious example being AMP (which is bad).
This seems subtle, but it really is a fundamental shift in the dynamic. As Google moves more and more content into its site, it stops being an index of sources of information and starts asserting information itself. It’s the Wikipedia-as-a-source problem; “Google says” isn’t enough, can’t be enough.
Google isn’t good at search
But for all Google’s talk about providing good information ond preventing spam, Google search results (and search results in general) are actually very bad at present. Most queries about specific questions result in either content scraped from other sites or just a slurry of SEO mush, the aesthetics of “information” with none of the substance. (For my non-technical friends, see the recipe blog problem.)
As I’ve said before, there needs to be a manual flag Google puts on authoritative sources. It’s shameful how effective spam websites are on technical content. Official manuals on known, trusted domains should rise to the top of results. This doesn’t solve the semantic search problem, but it’s an obvious remedy to an obvious problem, and it’s frankly shameful that Google and others haven’t been doing it for years already.
I saw Michael Seibel recently sum up the current state of affairs:
Michael Seibel (@mwseibel): A recent small medical issue has highlighted how much someone needs to disrupt Google Search. Google is no longer producing high quality search results in a significant number of important categories.
Health, product reviews, recipes are three categories I searched today where top results featured clickbait sites riddled with crappy ads. I’m sure there are many more. Feel free to reply to the thread with the categories where you no longer trust Google Search results.
I’m pretty sure the engineers responsible for Google Search aren’t happy about the quality of results either. I’m wondering if this isn’t really a tech problem but the influence of some suit responsible for quarterly ad revenue increases.
…
The more I think about this, the more it looks like classic short term thinking. Juice ad revenue in the short run. Open the door to complete disruption in the long run…
Trying to use algorithms to solve human problems
But I’m not going to be too harsh on Google’s sourcing algorithm. It’s probably a very good information sourcing algorithm. The problem is that even a very good information sourcing algorithm can’t possibly work in anything approaching fit-for-purpose here.
The task here is “process this collection of information and determine both which sources are correct and credible and what those sources’ intended meanings are.” This isn’t an algorithmic problem. Even just half of that task — “understanding intended meaning” — is not only not something computers are equipped to do but isn’t even something humans are good at!
By its very nature Google can’t help but “take everything it reads on the internet at face value” (which, for humans, is just basic operating knowledge). And so you get the garbage-in, garbage-out problem, at the very least.
Google can’t differentiate subculture context. Even people are bad at this! And, of course, Google can “believe” wrong information, or just regurgitate terrible advice.
Fri Sep 04 02:46:34 +0000 2020Love how Google automatically pulls data from websites now and presents it so you don’t ever need to click to get the necessary info!
Anyway off to cancel my appointment with a tax accountant I had for next week!


But the problem is deeper than that, because the whole premise that all questions have single correct answers is wrong. There exists debate on points of fact. There exists debate on points of fact! We haven’t solved information literacy yet, but we haven’t solved information yet either. The interface that takes in questions and returns single correct answers doesn’t just need a very good sourcing function, it’s an impossible task to begin with. Not only can Google not automate information literacy, the fact that they’re pretending they can is itself incredibly harmful.
But the urge to solve genuinely difficult social, human problems with an extra layer of automation pervades tech culture. It essentially is tech culture. (Steam is one of the worst offenders.) And, of course, nobody in tech ever got promoted for replacing an algorithm with skilled human labor. Or even for pointing out that they were slapping an algorithm on an unfit problem. Everything pulls the other direction.
Dangers of integrating these services into society
Of course, there’s a huge incentive to maximize the number of queries you can respond to. Some of that can be done with reliable data sourcing (like Wolfram|Alpha does), but there are a lot of questions whose answers aren’t in a feasible data set. And, according to Google, 15% of daily searches are new queries that have never been made before, so if your goal is to maximize how many questions you can answer (read: $$$), human curation isn’t feasible either.
But if you’re Google, you’ve already got most of the internet indexed anyway. So… why not just pull from there?
Well, I mean, we know why. The bad information, and the harm, and the causing of preventable deaths, and all that.
And this bad information is at its worst when it’s fed into personal assistants. Your Alexas, Siris, Cortanas all want to do exactly this: answer questions with actionable data.
The problem is the human/computer interface is completely different with voice assistants than it is with traditional search. When you search and get a featured snippet, it’s on a page with hundreds of other articles and a virtually limitless number of second opinions. The human has the agency to do their own research using the massively powerful tools at their disposal.
Not so with a voice assistant. They have the opportunity to give zero-to-one answers, which you can either take or leave. You lose that ability to engage with the information or do any followup research, and so it becomes much, much more important for those answers to be good.
And they’re not.
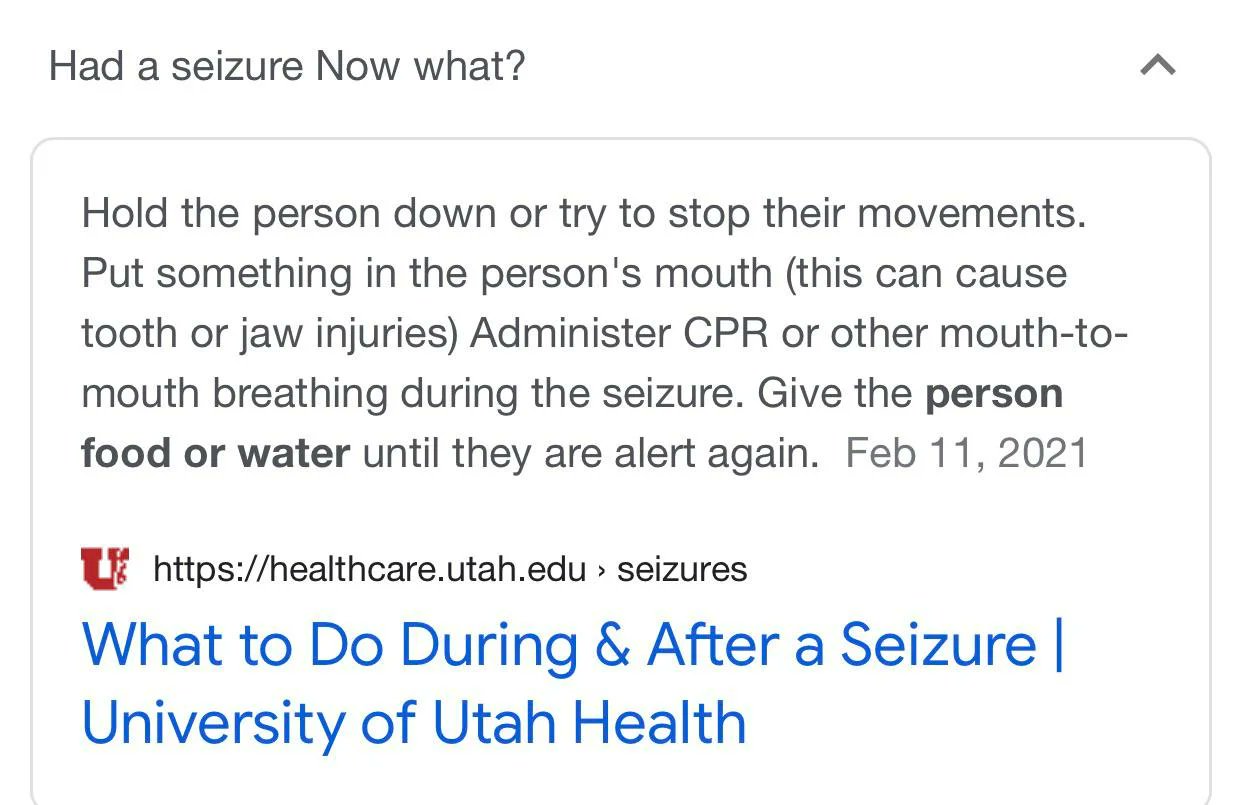
Let’s revisit that “had a seizure, now what” question, but this time without the option to click through to the website to see context.
Replying to soft:Sat Oct 16 22:16:57 +0000 2021@soft Oh no, it’s just as worse on Google Home. This will legit get someone killed.

Oh no.
And of course these aren’t one-off problems, either. We see these stories regularly. Like just back in December, when Amazon’s Alexa told a 10 year old to electrocute herself on a wall outlet. Or Google again, but this time killing babies.
The insufficient responses
Let’s pause here for a moment and look at the response to just one of these incidents: the seizure one. Google went with the only option they had (other than discontinuing the ill-conceived feature, of course): case-by-case moderation.
Replying to soft:Sun Oct 17 01:58:50 +0000 2021@soft We're looking at this now to get it resolved.

Now, just to immediately prove the point that case-by-case moderation can’t deal with a fundamentally flawed problem like this, they couldn’t even fix the seizure answers
Replying to dannysullivan:Sun Oct 17 09:41:47 +0000 2021@dannysullivan @soft Just a note, the problematic result summary is removed for that particular search now, but still shows up for "Had seizure now what?" "Seizure now what?" That entire answer summary needs to be removed.

See, it wasn’t fixed by ensuring future summaries of life-critical information would be written and reviewed by humans, because that’s a cost. A necessary cost for the feature, in this case, but that doesn’t stop Google from being unwilling to pay it.
And, of course, the only reason this got to a Google engineer at all is that the deadly advice wasn’t followed, the person survived, and the incident blew up in the news. Even if humans could filter through the output of an algorithm that spits out bad information (and they can’t), best-case scenario we have a system where Google only lies about unpopular topics.
COVID testing
And then we get to COVID.
Now, with all the disinformation about COVID, sites like Twitter and YouTube have taken manual steps to try to specifically provide good sources of information when people ask, which is probably a good thing.
But even with those manual measures in place, when Joe Biden told people to “Google COVID test near me” in lieu of a national program, it raised eyebrows.
Wed Jan 05 16:15:01 +0000 2022I know COVID testing remains frustrating, but we are making improvements.
In the last two weeks we have stood up federal testing sites all over this country — and we are adding more each day.
Google “COVID test near me” to find the nearest site where you can get a test.

Now, apparently there was some effort to coordinate manually sourcing of reliable information for COVID testing, but it sounds like that might have some issues too:
Wed Jan 05 19:36:56 +0000 2022::whispers:: Volunteers were doing this work since mid-March 2020 and I was in touch with senior Biden Administration officials in Nov. 2020…they went radio silent, and volunteer enthusiasm waned so the effort shuttered in mid-October 2021. twitter.com/hacks4pancakes…

So now, as Kamala Harris scolds people for even asking about Google alternatives in an unimaginably condescending interview, we’re back in the middle of it. People are going to use Google itself as the authoritative source of information, because the US Federal government literally gave that as the only option. And so there will be scams, and misinformation, and people will be hurt.
But at least engineers at Google know about COVID. At least, on this topic, somebody somewhere is going to try to filter out the lies. For the infinitude of other questions you might have? You’ll get an answer, but whether or not it kills you is still luck of the draw.
Related Reading
- Safiya Umoja Noble, “Algorithms of Oppression - How Search Engines Reinforce Racism”
- Ax Sharma, “Amazon Alexa slammed for giving lethal challenge to 10-year-old girl”
- Alexa tells 10-year-old girl to touch live plug with penny - BBC News
- Alexis Hancock, “Google’s AMP, the Canonical Web, and the Importance of Web Standards”
- Tobie Langel, re: Alexa bbc article
- Jon Porter, “Zelda recipe appears in serious novel by serious author after rushed Google search”
- Breaking911, “VP Kamala Harris to Americans who can’t find a COVID test: “Google It””
- Reddit, “Do food bloggers realize how awful their recipe pages are?”
- Cory Doctorow, “Backdooring a summarizerbot to shape opinion”
- Microsoft, “Microsoft’s New Search at Bing.com Helps People Make Better Decisions”
- Russell Foltz-Smith, “Reactions to Wolfram|Alpha from around the Web”
- Nick Slater, “How SEO Is Gentrifying the Internet”
- Ed Z, “The Rot Economy”
- Google, “YouTube Misinformation - How YouTube Works”
- Google, “Our approach to Search”
- Google, “Responses”
- Google, “How Google’s featured snippets work”
Tue Apr 12 10:51:51 +0000 20222000: “We want to get you out of Google and to the right place as fast as possible”: Larry Page
2022: We want to keep you inside Google, which we consider the right place, as much as possible!
Source: 2000 screenshot/Archive.org


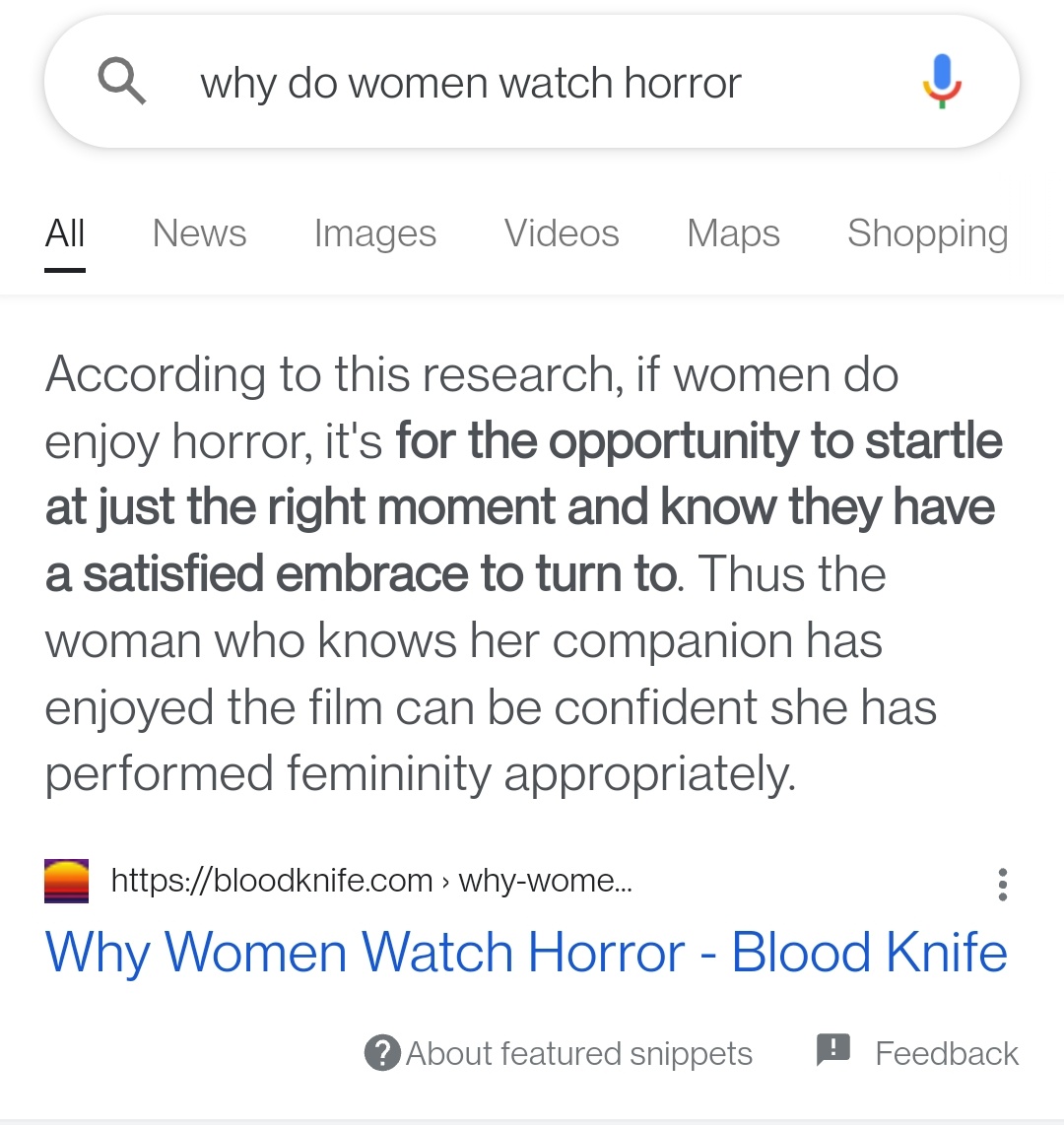
Fri May 27 05:24:39 +0000 2022Google snippets suck so bad. We have an entire article on why women watch horror and it chooses to excerpt the part that is only included to say "this is what people used to think but it's wrong and based on poor research."


2023-02-08T22:20:37.141ZOMG.
1. Google has some bad summarization telling people that throwing batteries into the ocean is good.
2. News articles were written about this.
3. Bing's summarization interprets these articles as advice to ... throw batteries in the ocean!🤦
(Apparently none of this is AI... yet.)

