OS-Level Age Attestation is the Good One
OS-Level Age Attestation is the Good One
There’s a coordinated effort to use the “child safety” euphemism to cripple the internet with identity verification mandates. That’s bad. But buried in the mix there’s a genuinely good idea with enough political capital that it might stick around and do some good.
Every time I’ve tried to write an article on the topic of child internet safety my energy has fizzled into depression, because as one researches the topic it becomes obvious that everyone with any relevant power is refusing to solve the problem on purpose. It’s demoralizing and it’s been mostly useless for me to do any thought work in this area.
But California’s age attestation bill might be an exception to this. Because it’s age attestation, not age verification, it looks like a significant political step in the right direction, and with the right focus it could do a lot of good. A lot of people have (fairly!) assumed attestation was age verification or at least lays the groundwork, but I think this isn’t the case. There is always the danger of future bad legislation, but OS attestation doesn’t pave the way for it, it provides a strong defense against it. We need a good idea to win the child safety war, not because we’re in dire need of more online child safety, but because addressing the real concerns correctly blocks a whole slew of impossibly dangerous policies.
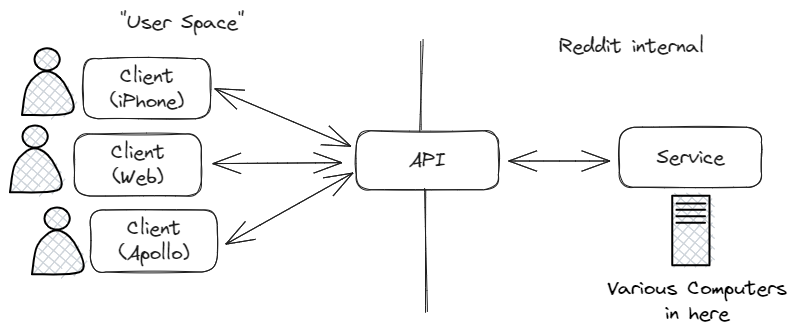
My ideal age filtering tool is a system of client attestation with trust rooted in the adult administrator, provided by an OS-level API provided as preemptive verification, enforced by compliant browsers and application stores. And we’re shockingly close to that.
There is room for improvement
People on the privacy side of the age verification war — my side — will argue that parents already have everything they need for comprehensive web filtering if they want to use it. I think this isn’t quite true; there’s one notable architectural gap that a technical solution could meaningfully fill.
There are many existing content filtering tools geared toward child safety but their weakness is that they’re reactive. Traffic filters can identify and block traffic from known websites and on-device content filters can try to detect and block specific content. But this requires the user reacting and defending against every possible source and behavior. It’s the same cat-and-mouse game as adblockers. And like adblockers, the more closed down the system is — like iOS or gaming consoles — the harder it is for developers to make exactly the right product.
The internet sometimes assumes minors are supervised — since they have parental consent to have the device in the first place — but this often isn’t the case. It’s very common for minors to have their own phones or tablets with unsupervised access. When they’re online or downloading apps, they’re not sitting with a parent, they’re unsupervised, roaming children. Parents are dropping their kids off in the city.
This isn’t inherently bad; it seems like parents and children both want children to be able to exist independently without granular supervision, and so there’s a desire to make that situation safer. That shouldn’t come at the cost of any adult liberty or even the liberty of children with parental consent; it just means we want an ecosystem that allows for unsupervised children to exist within it.
Right now the burden is on parents to be active defenders protecting their children from a vast ecosystem of companies investing research and capital into optimizing how efficiently they can exploit money and data out of everyone in the world. It would be a meaningful improvement if there were a safe way to prevent some of this exploitation by putting reasonable requirements on providers, so long as this can be done in a way that doesn’t cause more problems.
Political pressure for “child safety” is exploitable
But the lack of a perfect parental control system isn’t the main problem here. The real danger is the push for online identity verification using child safety as a justification.
Smart and privacy conscious people demand “No age verification” (quite reasonably!), but that doesn’t offer the quick fix people are looking for. More importantly, it doesn’t relieve the political pressure and so doesn’t take away the excuses of tyrants.
Normally “do nothing” would be the safest option here, but the danger of uninformed and reactionary voters means there is a great deal to gain by satisfying the concerns safely instead of letting the solution be evil. A technical standard for parents to somehow identify their children as children is the relief valve for dangerous political pressure. This doesn’t appease the fascists and censors. This doesn’t cede them any ground and it’d be wrong to try to; there’s no satisfying that hunger and it’s a dangerous mistake to feed it. What it does is actually improve the material conditions for the people they’re trying to trick.
A proactive system that puts some of the burden for protecting children on those companies is a real relief to this, and it would be a meaningful improvement if something could address this without causing bigger problems.
Taxonomy
There are three basic categories of age filtering: nothing, client attestation, and client verification. These provide services varying levels of confidence in their knowledge of users. (It’s tempting to simplify confidence to labels like “strong” or “weak” but it’s important to think about what’s actually being secured, and from who.) Different people call these different things, but here’s my taxonomy with the labels I’ll use.