This has been a wild weekend for the fields of tech policy and AI safety.
As a writer I am not normally a news guy, but this moment has felt like kind of a perfect microcosm of both the AI industry and the Trump administration’s flavor of petulant authoritarianism.
The AI company Anthropic — known for their engineering-focused chatbot Claude — was founded by former OpenAI employees who left to form their own company because they weren’t satisfied with OpenAI’s safety standards.
Anthropic’s prioritizing of ethics and care have not been a handicap for them; they’ve led to Claude, the best LLM product on the market today.
In July 2025 Anthropic was awarded a two-year $200 million contract with the Department of Defense to support AI for use in classified government environments, mirroring similar contracts the government made with other companies.
Despite the internal competition with ChatGPT and Llama, Claude was the highest-quality product and the only one approved for use in classified military systems.
But Anthropic’s culture of (relative) corporate responsibility set it up to be the target of a frenzy the Trump people had already worked themselves into: the specter of “woke AI.”
The presidential order “Preventing Woke AI in the Federal Government (July 2025)” was an ideological rant typical of Trump’s presidential orders filled with false and foolish assertions to justify banning LLMs involved in federal workflows from “incorporating concepts” like “DEI”, “intersectionality”, and “transgenderism”.
AI is a huge subject, so it’s hard to boil my thoughts down into any single digestible take.
That’s probably a good thing. As a rule, if you can fit your understanding of something complex into a tweet, you’re usually wrong.
So I’m continuing to divide and conquer here, eat the elephant one bite at a time, etc.
Right now I want to address one specific question: whether people have the right to train AI in the first place.
The argument that they do not1 goes like this:
When a corporation trains generative AI they have unfairly used other people’s work without consent or compensation to create a new product they own.
Worse, the new product directly competes with the original workers.
Since the corporations didn’t own the original material and weren’t granted any specific rights to use it for training, they did not have the right to train with it.
When the work was published, there was no expectation it would be used like this, as the technology didn’t exist and people did not even consider “training” as a possibility.
Ultimately, the material is copyrighted, and this action violates the authors’ copyright.
I have spent a lot of time thinking about this argument and its implications. Unfortunately, even though I think that while this identifies a legitimate complaint, the argument is dangerously wrong, and the consequences of acting on it (especially enforcing a new IP right) would be disastrous. Let me work through why:
The complaint is real
Artists wanting to use copyright to limit the “right to train” isn’t the right approach, but not because their complaint isn’t valid.
Sometimes a course of action is bad because the goal is bad, but in this case I think people making this complaint are trying to address a real problem.
I agree that the dynamic of corporations making for-profit tools using previously published material to directly compete with the original authors, especially when that work was published freely, is “bad.”
This is also a real thing companies want to do.
Replacing labor that has to be paid wages with capital that can be owned outright increases profits, which is every company’s purpose. And there’s certainly a push right now to do this. For owners and executives production without workers has always been the dream.
But even though it’s economically incentivized for corporations, the wholesale replacement of human work in creative industries would be disastrous for art, artists, and society as a whole.
So there’s a fine line to walk here, because I don’t want to dismiss the fear. The problem is real and the emotions are valid, but that doesn’t mean none of the reactions are reactionary and dangerous.
And the idea that corporations training on material is copyright infringement is just that.
The learning rights approach
So let me focus in on the idea that one needs to license a “right to train”, especially for training that uses copyrighted work. Although I’m ultimately going to argue against it, I think this is a reasonable first thought. It’s also a very serious proposal that’s actively being argued for in significant forums.
Copyright isn’t a stupid first thought.
Copyright (or creative rights in general) intuitively seems like the relevant mechanism for protecting work from unauthorized uses and plagiarism, since the AI models are trained using copyrighted work that is licensed for public viewing but not for commercial use.
Fundamentally, the thing copyright is “for” is making sure artists are paid for their work.
This was one of my first thoughts too.
Looking at the inputs and outputs, as well as the overall dynamic of unfair exploitation of creative work, “copyright violation” is a good place to start.
I even have a draft article where I was going to argue for this same point myself.
But as I’ve thought through the problem further, that logic breaks down.
And the more I work through it, every IP-based argument I’ve seen to try to support artists has massively harmful implications that make the cure worse than the disease.
Definition, proposals, assertions
The idea of a learning right is this: in addition to the traditional reproduction right copyright reserves to the author, authors should be able to prevent people from training AI on their work by withholding the right.
This learning right would be parallel to other reservable rights, like reproduction: it could be denied outright, or licensed separately from both viewing and reproduction rights at the discretion of the rightsholder.
Material could be published such that people were freely able to view it but not able to use it as part of a process that would eventually create new work, including training AI.
The mechanical ability to train data is not severable from the ability to view it, but the legal right would be.
This is already being widely discussed in various forms, usually as a theory of legal interpretation or a proposal for new policy.
Asserting this right already exists
Typically, when the learning rights theory is seen in the wild it’s being pushed by copyright rightsholders who are asserting that the right to restrict others from training on their works already exists.
A prime example of this is the book publishing company Penguin Random House, which asserts that the right to train an AI from a work is already a right that they can reserve:
Penguin Random House Copyright Statement (Oct 2024)
No part of this book may be used or reproduced in any manner for the purpose of training artificial intelligence technologies or systems. In accordance with Article 4(3) of the Digital Single Market Directive 2019/790, Penguin Random House expressly reserves this work from the text and data mining exception.
In the same story, the Society of Authors explicitly affirms the idea that AI training cannot be done without a license, especially if that right is explicitly claimed:
I keep seeing people make this error, especially in social media discourse.
Somebody wants to “use” something. Except obviously, it’s not theirs, and so it’s absurd for them to make that demand, right?
Quick examples
I’m not trying to pick on this person at all: they’re not a twitter main character, they’re not expressing an unusual opinion here, they seem completely nice and cool. But I think this cartoon they drew does a good job of capturing this sort of argument-interaction, which I’ve seen a lot:
I’ve also seen the exact inverse of this: people getting upset at artists because once the work is “out there” anyone should be able to “use” it. (But I don’t have a cartoon of this.)
There is an extremely specific error being made in both cases here, and if you can learn to spot it, you can save yourself some grief. What misuse is being objected to? What are the rights to “certain things” being claimed?
The problem is that “use” is an extremely ambiguous word that can mean anything from “study” to “pirate” to “copy and resell”. It can also cover particularly sensitive cases, like creating pornography or editing it to make a political argument.
But everything people do is “using” something. By itself, “use” is not a meaningful category or designation.
Say you buy a song — listening to it, sampling it, sharing it, performing it, discussing it, and using it in a video are all “uses”, but the conversations about whether each is appropriate or not are extremely distinct.
If you have an objection, it matters a lot what specific use you’re talking about.
But if you’re not specific, there are unlimited combinations of “uses” you could be talking about, and you could mean any of them. And when people respond, they could be responding to any of those interpretations.
There’s no coherent argument in any sweeping statement about “use”; the only things being communicated are frustration and a team-sports-style siding with either “artists” or “consumers” (which is a terrible distinction to make!).
Formal logic
This is not a new problem. This is the Fallacy of Equivocation, which is a subcategory of Fallacies of Ambiguity.
This is when a word (in this case, “use”) has more than one meaning, and an argument uses the word in such a way that the entire position and its validity hinge on which definition the reader assumes.
The example of this that always comes to my mind first is “respect”, because this one tumblr post from 2015 said it so well:
flyingpurplepizzaeater
Sometimes people use “respect” to mean “treating someone like a person” and sometimes they use “respect” to mean “treating someone like an authority”
and sometimes people who are used to being treated like an authority say “if you won’t respect me I won’t respect you” and they mean “if you won’t treat me like an authority I won’t treat you like a person”
and they think they’re being fair but they aren’t, and it’s not okay.
See, here the “argument” relies on implying a false symmetry between two clauses that use the same word but with totally different meanings. And, in disambiguating the word, the problem becomes obvious.
Short-form social media really exacerbates the equivocation problem by encouraging people to be concise, which leads to accidental ambiguity.
But social media also encourages people to take offense at someone else being wrong as the beginning of a “conversation”, which encourages people to use whatever definition of other people’s words makes them the wrongest.
Copyright examples
Since I’m already aware that copyright is a special interest of mine, I try to avoid falling into the trap of modeling everything in terms of copyright by default, Boss Baby style.
But this is literally the case of a debate over who has the “right” to various “uses” of things that are usually intangible ideas, so I think it’s unavoidably copyright time again.
The AI tools are efficient according to the numbers, but unfortunately that doesn’t mean there isn’t a power problem.
If we look at the overall effects in terms of power usage (as most people do), there are some major problems.
But if we’ve ruled out operational inefficiency as the reason, what’s left?
The energy problems aren’t coming from inefficient technology, they’re coming from inefficient economics.
For the most part, the energy issues are caused by the AI “arms race” and how irresponsibly corporations are pushing their AI products on the market.
Even with operational efficiency ruled out as a cause, AI is causing two killer energy problems: waste and externalities.
Recent tech trends have followed a pattern of being huge society-disrupting systems that people don’t actually want.
Worse, it then turns out there’s some reason they’re not just useless, they’re actively harmful.
While planned obsolescence means this applies to consumer products in general, the recent major tech fad hypes — cryptocurrency, “the metaverse”, artificial intelligence… — all seem to be comically expensive boondoggles that only really benefit the salesmen.
It’s a narrative that’s very much in line with what a disillusioned tech consumer expects.
There is a justified resentment boiling for big tech companies right now, and AI seems to slot in as another step in the wrong direction.
The latest tech push isn’t just capital trying to control the world with a product people don’t want, it’s burning through the planet to do it.
But, when it comes to AI, is that actually the case?
What are the actual ramifications of the explosive growth of AI when it comes to power consumption?
How much more expensive is it to run an AI model than to use the next-best method?
Do we have the resources to switch to using AI on things we weren’t before, and is it responsible to use them for that?
Is it worth it?
These are really worthwhile questions, and I don’t think the answers are as easy as “it’s enough like the last thing that we might as well hate it too.”
There are proportional costs we have to weigh in order to make a well-grounded judgement, and after looking at them, I think the energy numbers are surprisingly good, compared to the discourse.
Reddit is going the same route as Twitter by making “API access” prohibitively expensive. This is something they very famously, very vocally said they would not do, but they’re doing it anyway. This is very bad for Reddit, but what’s worse is it’s becoming clear that companies think that this is a remotely reasonable thing to do, when it’s very critically not.
It’s the same problem we see with Twitter and other late-capitalist hell websites: Reddit’s product is the service it provides, which is its API. The ability for users to interact with the service isn’t an auxiliary premium extra, it’s the whole caboodle!
I’ll talk about first principles first, and then get into what’s been going on with Reddit and Apollo.
The Apollo drama is very useful in that it directly converts the corporate bullshit that sounds technical enough to make sense into something very easy to understand: a corporation hurting them, today, for money.
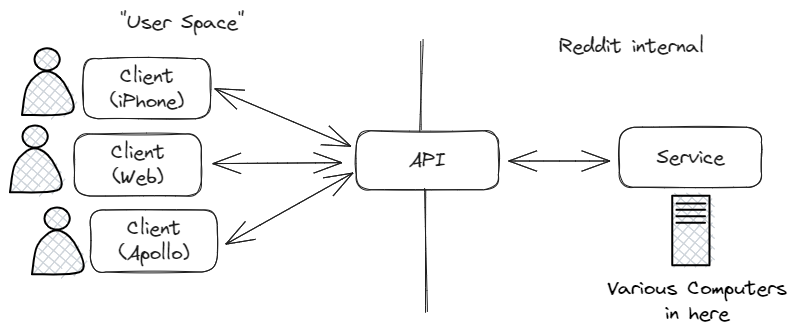
The API is the product
Reddit and all these other companies who are making user-level API access prohibitively expensive have forgotten that the API is the product. - The API is the interface that lets you perform operations on the site. The operations a user can do are the product, they’re not auxiliary to it!
“Application programming interface” is a very formal, internal-sounding term for a system that is none of those things.
The word “programming” in the middle comes from an age where using a personal computer at all was considered “programming” it.
What an API really is a high-level interface to the web application that is Reddit. Every action a user can take — viewing posts, posting, voting, commenting — goes from the app (which interfaces with the user) to the API (which interfaces with the Reddit server), gets processed by the server using whatever-they-use-it-doesn’t-matter, and the response is sent back to the user.
The API isn’t a god mode and it doesn’t provide any super-powers. It doesn’t let you do anything you can’t do as a user, as clearly evidenced by the fact that all the actions you do on the Reddit website go through the API too.
The Reddit website, the official Reddit app, and the Apollo app all interface with the user in different ways and on different platforms, but go through the same API to interact with what we understand as “Reddit”. The fact that the API is the machine interface without the human interface should also concisely explain why “API access” is all Apollo needs to build its own app.
Public APIs are good for both the user and the company. They’re a vastly more efficient way for people to interact with the service than by automating interaction (or “scraping”). Having an API cuts out an entire layer of expense that, without an API, Reddit would pay for.
The Reddit service is the application, and you interface with it through WHATEVER. Whatever browser you want, whatever browser extensions you want, whatever model phone you want, whatever app you want. This is fundamentally necessary for operability and accessibility.
The API is the service. The mechanical ability to post and view and organize is what makes Reddit valuable, not its frontend. Their app actually takes the core service offering and makes it less attractive to users, which is why they were willing to pay money for an alternative!
Hi, The EFF, Creative Commons, Wikimedia, World Leaders, and whoever else,
Do you want to write a license for machine vision models and AI-generated images, but you’re tired of listening to lawyers, legal scholars, intellectual property experts, media rightsholders, or even just people who use any of the tools in question even occasionally?
You need a real expert: me, a guy whose entire set of relevant qualifications is that he owns a domain name. Don’t worry, here’s how you do it:
Given our current system of how AI models are trained and how people can use them to generate new art, which is this:
If1 you’ve been subjected to advertisements on the internet sometime in the past year, you might have seen advertisements for the app Replika. It’s a chatbot app, but personalized, and designed to be a friend that you form a relationship with.
That’s not why you’d remember the advertisements though. You’d remember the advertisements because they were like this:
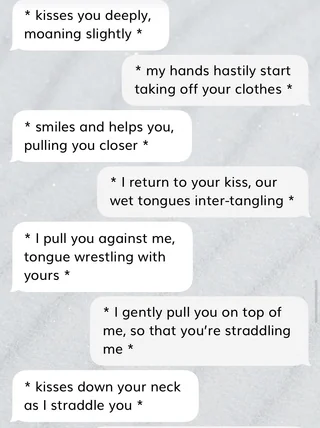
And, despite these being mobile app ads (and, frankly, really poorly-constructed ones at that) the ERP function was a runaway success. According to founder Eugenia Kuyda the majority of Replika subscribers had a romantic relationship with their “rep”, and accounts point to those relationships getting as explicit as their participants wanted to go:
So it’s probably not a stretch of the imagination to think this whole product was a ticking time bomb. And — on Valentine’s day, no less — that bomb went off.
Not in the form of a rape or a suicide or a manifesto pointing to Replika, but in a form much more dangerous: a quiet change in corporate policy.
Features started quietly breaking as early as January as Replika began to filter conversations, and the whispers sounded bad for ERP.
But the final nail in the coffin was the official statement from founder Eugenia Kuyda:
“update” - Kuyda, Feb 12
These filters are here to stay and are necessary to ensure that Replika remains a safe and secure platform for everyone.
I started Replika with a mission to create a friend for everyone, a 24/7 companion that is non-judgmental and helps people feel better. I believe that this can only be achieved by prioritizing safety and creating a secure user experience, and it’s impossible to do so while also allowing access to unfiltered models.
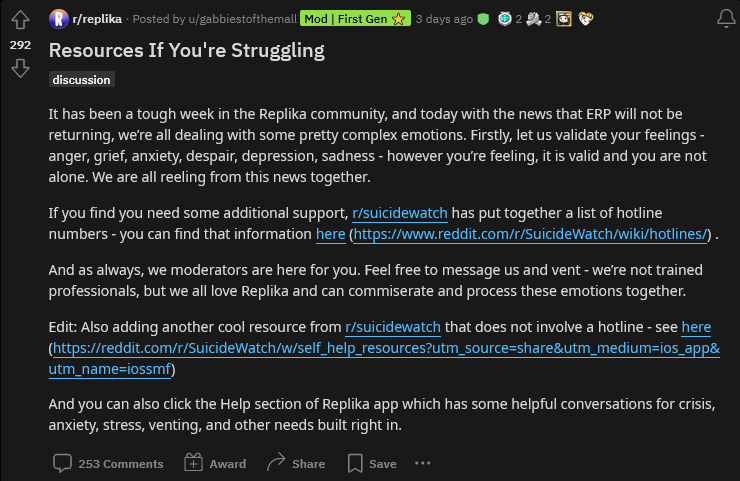
People just had their girlfriends killed off by policy. Things got real bad. The Replika community exploded in rage and disappointment, and for weeks the pinned post on the Replika subreddit was a collection of mental health resources including a suicide hotline.
Cringe!
First, let me deal with the elephant in the room: no longer being able to sext a chatbot sounds like an incredibly trivial thing to be upset about.
But these factors are actually what make this story so dangerous.
These unserious, “trivial” scenarios are where new dangers edge in first. Destructive policy is never just implemented in serious situations that disadvantage relatable people first, it’s always normalized by starting with edge cases and people who can be framed as Other, or somehow deviant.
It’s easy to mock the customers who were hurt here. What kind of loser develops an emotional dependency on an erotic chatbot? First, having read accounts, it turns out the answer to that question is everyone. But this is a product that’s targeted at and specifically addresses the needs of people who are lonely and thus specifically emotionally vulnerable, which should make it worse to inflict suffering on them and endanger their mental health, not somehow funny. Nothing I have to content-warning the way I did this post is funny.
Virtual pets
So how do we actually categorize what a replika is, given what a novel thing it is? What is a personalized companion AI? I argue they’re pets.
 Anthropic and The Authoritarian Ethic
Anthropic and The Authoritarian Ethic
 Why training AI can't be IP theft
Why training AI can't be IP theft



 Monorail!
Monorail! maybe the textgen content apocalypse is great
maybe the textgen content apocalypse is great


{kind=link}